Overview
GREASE is command-line tool, Ghidra plug-in, and Haskell library that checks properties about binaries using under-constrained symbolic execution.
grease supports analysis of ELF executables or shared objects containing AArch32, PowerPC, or x86_64 code. grease can also analyze LLVM bitcode.
Demo
Consider the following function derived from libpng. Can you spot the bug?1
void /* PRIVATE */
png_check_chunk_length(png_const_structrp png_ptr, const unsigned int length)
{
png_alloc_size_t limit = PNG_UINT_31_MAX;
# ifdef PNG_SET_USER_LIMITS_SUPPORTED
if (png_ptr->user_chunk_malloc_max > 0 &&
png_ptr->user_chunk_malloc_max < limit)
limit = png_ptr->user_chunk_malloc_max;
# elif PNG_USER_CHUNK_MALLOC_MAX > 0
if (PNG_USER_CHUNK_MALLOC_MAX < limit)
limit = PNG_USER_CHUNK_MALLOC_MAX;
# endif
if (png_ptr->chunk_name == png_IDAT)
{
png_alloc_size_t idat_limit = PNG_UINT_31_MAX;
size_t row_factor =
(png_ptr->width * png_ptr->channels * (png_ptr->bit_depth > 8? 2: 1)
+ 1 + (png_ptr->interlaced? 6: 0));
if (png_ptr->height > PNG_UINT_32_MAX/row_factor)
idat_limit=PNG_UINT_31_MAX;
else
idat_limit = png_ptr->height * row_factor;
row_factor = row_factor > 32566? 32566 : row_factor;
idat_limit += 6 + 5*(idat_limit/row_factor+1); /* zlib+deflate overhead */
idat_limit=idat_limit < PNG_UINT_31_MAX? idat_limit : PNG_UINT_31_MAX;
limit = limit < idat_limit? idat_limit : limit;
}
// ...
}
grease can:
$ clang test.c -o test
$ grease test
Finished analyzing 'png_check_chunk_length'. Possible bug(s):
At 0x100011bd:
div: denominator was zero
Concretized arguments:
rcx: 0000000000000000
rdx: 0000000000000000
rsi: 0000000000000000
rdi: 000000+0000000000000000
r8: 0000000000000000
r9: 0000000000000000
r10: 0000000000000000
000000: 54 41 44 49 01 00 00 00 f9 ff ff ff 00 00 00 00 00 80
This output says that png_check_chunk_length will divide by zero when rdi points to an allocation holding the bytes 54 41 44 .... Indeed, if we add the following main function:
int main() {
char data[] = {0x54, 0x41, 0x44, 0x49, 0xf9, 0x00, 0x00, 0x00, 0x01, 0xb7, 0x3e, 0x9b, 0x00, 0x00, 0x00, 0x00, 0x00, 0x80};
png_check_chunk_length((png_const_structrp)data, 0);
return 0;
}
We see exactly what grease described:
$ clang test.c -o test
$ ./test
Floating point exception (core dumped)
This test-case is based on CVE-2018-13785. The complete example and accompanying license and copyright notice are available at tests/refine/neg/libpng-cve-2018-13785/test.c in the GREASE source repository.
Algorithm
The analysis performed is roughly the following:
- The binary is disassembled and converted into a control-flow graph IR.
greasesymbolically simulates the entrypoint using the most general possible preconditions (all registers hold fresh symbolic variables).- If an out-of-bounds memory read or write occurs, the precondition is refined by growing allocated / initialized memory. For example, if an out-of-bounds read occurs at an offset of the address in
r8, we refine the precondition to make sure thatr8points to a region of initialized memory big enough to contain the offset. - This process of simulation and refinement repeats itself until either (1) no errors occur (in which case we move on) or (2) errors occur and we do not have heuristics to refine based on any of the errors (in which case we concretize the arguments, report an error, and exit).
- Now that we have found a memory layout that allows us to simulate the entrypoint without error, we instrument the control-flow graph with new instructions that encode further assertions.
- Finally, we run the instrumented control-flow graph with the inferred memory layout precondition. If all collected assertions pass, we report that the property holds. Otherwise, we report that the property does not hold.
For more details, see Refinement.
For a capability comparison with other similar tools, see Comparison with other tools and frameworks.
Acknowledgements
This material is based upon work supported by the Defense Advanced Research Projects Agency under Contract No. W31P4Q-22-C-0017 and W31P4Q-23-C-0020
Any opinions, findings and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the Defense Advanced Research Projects Agency or the U.S. Government.
Copyright
Copyright (c) Galois, Inc. 2024.
Quick start
This page will get you up and running as quickly as possible with the GREASE CLI. For more detailed instructions, see Installation and Usage.
First, compile a binary to analyze with GREASE:
echo 'int main() { return 0; }' > test.c
clang test.c -o test
Then, run GREASE in a Docker container:
docker run --rm -v "${PWD}:${PWD}" -w "${PWD}" ghcr.io/galoisinc/grease:nightly test
Note that GREASE only supports analysis of ELF executables, so this will work
best on Linux. If you're not using Linux, you can try running GREASE on one of
the binaries in its test suite, under grease-exe/tests.
Installation
GREASE can be installed via a Docker image, or as a standalone binary.
Using GREASE with Docker
The easiest way to get started with GREASE is with Docker.
Once you've downloaded or built a Docker image, see Usage for how to run it.
Using a pre-built Docker image
GREASE publishes Docker images built from the main branch to the GitHub
container registry. You can pull the latest image with:
docker pull ghcr.io/galoisinc/grease:nightly
docker tag ghcr.io/galoisinc/grease:nightly grease:latest
Building an image from source
First, fetch the source:
git clone https://github.com/GaloisInc/grease
cd grease
git submodule update --init
Then, build the image:
docker build . --tag grease:latest
Building a binary from source
See the developer's guide for how to build grease from source.
When run as a standalone binary, GREASE requires a recent version of one of the
following SMT solvers: bitwuzla, cvc4, cvc5, yices, or z3. GREASE is
currently tested against yices version 2.6.5 in CI. Appropriate versions of
these SMT solvers are already installed in the GREASE Docker image. grease
will default to using yices unless you manually specify a solver using the
--solver option.
Usage
This page describes the usage of the GREASE command-line interface.
Running the Docker image
To run GREASE from the Docker image:
docker run grease:latest <args>
For <args>, see below.
Some helpful Docker flags:
--rm: Delete the container after it exits-v "$PWD:$PWD" -w "$PWD": Mount your current directory into the Docker image and set it as the working directory
All together:
docker run --rm -v "$PWD:$PWD" -w "$PWD" grease:latest <args>
Running a standalone binary
grease -- <filename>
By default, GREASE analyzes every known function in the input program. You can use one of the following flags to specify specific entrypoints:
--symbol: Analyze a function with a specific symbol name (e.g.,main).--address: Analyze a function at a specific address.--{symbol,address}-startup-override: Like--{symbol,address}, but with a particular startup override. (For more information on startup overrides, see the overrides section.)--core-dump: Analyze the function most likely to contain the address where the core was dumped in the supplied core dump file.
By default, GREASE will treat <filename> as an ELF file and read the ELF
headers to determine whether it is AArch32, PowerPC, or x86_64. This behavior
can be overridden if <filename> ends in one of the following suffixes:
.armv7l.elf: 32-bit ARM ELF executable.ppc32.elf: 32-bit PowerPC ELF executable.ppc64.elf: 64-bit PowerPC ELF executable.x64.elf: x86_64 ELF executable.bc: LLVM bitcode
or one of the following, which are mostly useful for GREASE developers:
.armv7l.cbl: 32-bit ARM CFG written in macaw-symbolic Crucible syntax.ppc32.cbl: 32-bit PowerPC CFG written in macaw-symbolic Crucible syntax.x64.cbl: x86_64 CFG written in macaw-symbolic Crucible syntax.llvm.cbl: LLVM CFG written in crucible-llvm syntax
(Note that .ppc64.cbl files are not currently supported, as grease's 64-bit
PowerPC frontend currently requires a binary in order to work. See this
upstream issue for more
details.)
Try --help to see additional options.
Running on a non-ELF image
GREASE has some support for analyzing non-ELF (i.e., raw) position dependent executables (e.g. firmware images)
by loading a file at a fixed offset. The --raw-binary flag enables this mode. By default the image
is loaded at offset 0x0, which is likely not ideal for many binaries so an offset can be set with --load-base BASE_ADDR.
There are no symbols in a raw binary, so address entrypoints are the only valid entrypoints (i.e. --address).
Path strategies
GREASE supports a few different path strategies, which indicate how to handle
branching. A strategy can be specified using --path-strategy.
ssestands for static symbolic execution. In this mode, GREASE always merges paths at control-flow join points. This is the default.dfsstands for depth-first search. In this mode, GREASE never merges paths, and explores paths in a depth-first traversal.
Ghidra plugin
GREASE includes support for integrating with the Ghidra software reverse engineering suite via a plugin. The plugin works interfaces with a local GREASE installation and presents the results of GREASE's analysis to the user using Ghidra's graphical user interface.
Prerequisites
You will need to download Ghidra. We require Ghidra version or 11.0 or later, as this is when Ghidra introduced initial support for Rust binaries.
You will also need install a standalone grease binary, see
Installation.
You may optionally specify the path to your grease binary by setting the
GHIDRA_GREASE_BIN environment variable. If not set, the Ghidra plugin will
prompt for the path to your grease binary.
Similarly, you may optionally specify a directory containing GREASE override
files by setting the GHIDRA_GREASE_OVERRIDES environment
variable. If not set, the Ghidra plugin will prompt for a directory.
Plugin installation
Before starting, make sure you have installed Ghidra and installed the grease
binary, as described in the "Prerequisites" section above. Then perform the
following steps:
- In Ghidra, use
CodeBrowser Script Manager -> Manage Script Directoriesto add the<grease>/ghidra_scripts/path (where<grease>is the path to yourgreasecheckout). - In the Ghidra Script Manager, find
grease.pyand check theIn Toolcheckbox to addGREASE Analysisto theToolsmenu.
Plugin usage
After opening a binary in Ghidra, use Tools -> GREASE Analysis to start the
Ghidra plugin. If you haven't defined GHIDRA_GREASE_BIN or
GHIDRA_GREASE_OVERRIDES environment variables by this point, the plugin will
prompt you with a windows to locate the grease binary's location and the
GREASE override directory's locations, respectively.
The plugin will then prompt you to select function(s) to analyze. After picking
the function(s) of interest and clicking OK, the plugin will analyze the
function(s) using GREASE and display the results graphically. For example,
the screenshot below demonstrates the results of running the Ghidra plugin on a
main function with an uninitialized stack read at address 0x0010113b:
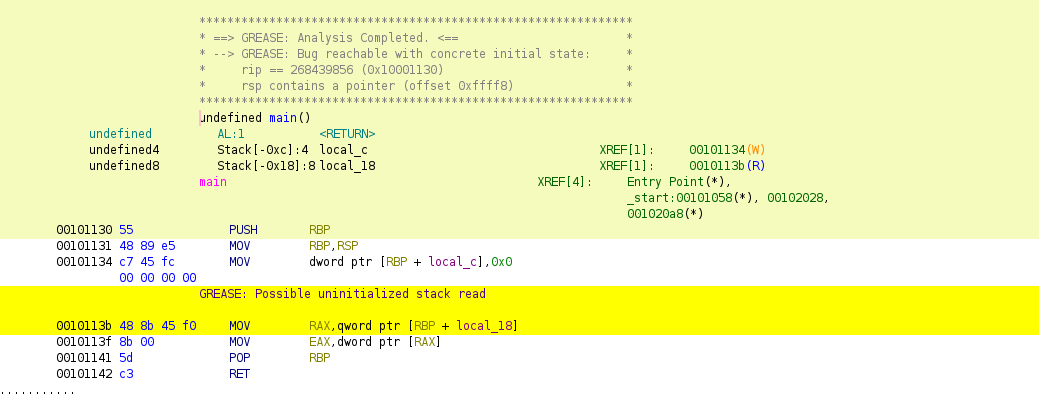
Ghidra batch plugin
This Ghidra plugin adds an analysis called "GREASE Analysis" which runs GREASE on all functions in a binary. The order the functions are analyzed in is given by a reverse topological sort of the callgraph. The goal is for the functionality in this plugin to eventually subsume the Ghidra script, but for now this analysis pass is better for use cases involving complete analysis of a large program where parallelism is required.
Prerequisites
You will need to build GREASE from source. See Installation for instructions.
Plugin installation
After building GREASE, you can use gradle to build the plugin zip file:
- Enter the ghidra plugin directory:
cd ghidra-plugin - Add the Ghidra install directory to
gradle.propertiesand uncomment the line - Run
./gradlew buildExtension - Optionally, the gradle file can install the extension directly with
./gradlew installExtension
After building the extension, a zip file will be in ./dist/ghidra_<VERSION>_<DATE>_ghidra-batch-plugin.zip which can be installed using the Ghidra Project menu:
- Open
File -> Install Extensions - Press the
+button and find the zip file in the file selector - Click the checkbox next to ghidra-plugin to enable the plugin
- Restart Ghidra
Plugin usage
Please see the GREASE topic in the Ghidra help menu for usage information.
Overrides
Overrides are models of functions that can be called during symbolic execution. Overrides can be used to model the effect of external functions, e.g., functions from dynamically-linked libraries. They can also be used to replace the definitions of complex functions in the target program with simpler models.
Some overrides are built-in to grease, e.g., for some functions
from libc, such as malloc. Users may also provide overrides, which take
priority over both built-in overrides and functions defined in the program under
analysis.
User-provided overrides are written in the Crucible S-expression language.
LLVM example
As an example, consider the following C program in the file prog.c:
#include <stdio.h>
extern void *id_ptr(void*);
int main() {
int x;
int *y = id_ptr(&x);
*y = 5;
printf("%i\n", x);
return 0;
}
If we compile this program to LLVM and disassemble it like so:1
clang -g -emit-llvm -O1 -c -fno-discard-value-names prog.c
llvm-dis prog.bc
Then the LLVM disassembly looks something like this:
define i32 @main() {
entry:
%x = alloca i32, align 4
%0 = bitcast i32* %x to i8*
%call = call i8* @id_ptr(i8* nonnull %0)
; -- snip --
ret i32 0
}
; -- snip --
declare i8* @id_ptr(i8*)
Since @id_ptr is not accompanied by a definition, GREASE fails to execute
this function:
grease prog.bc
-- snip --
Failed to infer precondition.
If id_ptr is supposed to be the identity function on (64-bit) pointers, we
can write the following LLVM override in id_ptr.llvm.cbl:
(defun @id_ptr ((p (Ptr 64))) (Ptr 64)
(start start:
(return p)))
and pass it to GREASE, which can then successfully execute the target function:
grease prog.bc --overrides id_ptr.llvm.cbl
5
-- snip --
All goals passed!
Note that the --overrides flag may be passed multiple times (e.g.,
--overrides foo.llvm.cbl --overrides bar.llvm.cbl) to supply multiple
overrides.
The only flags that are strictly necessary here are -c and -emit-llvm, the other flags aid the readability of the LLVM code.
Override file naming conventions
While GREASE does not enforce this convention, it is strongly encouraged to name override files as follows:
*.armv7l.cblfor AArch32 overrides*.llvm.cblfor LLVM overrides*.ppc32.cblfor PPC32 overrides*.ppc64.cblfor PPC64 overrides*.x64.cblfor x86_64 overrides
This naming scheme matches convention that GREASE requires for simulating S-expression programs.
Each <name>.*.cbl file is required to define a function named @<name>.
This is referred to as the file's public function, which is treated as an
override during simulation. All other functions defined in the file are
referred to as auxiliary functions. Auxiliary functions are not treated as
overrides during simulation, and they are effectively private to the file that
defines them.
Built-in overrides
In addition to the user-defined overrides described above, GREASE also provides a number of built-in overrides that are built directly into the tool. Many of the built-in overrides correspond to functions from libc. Unlike user-defined overrides, these overrides are always enabled by default, without needing the user to explicitly enable them.
If a user supplies an override of the same name as a built-in override, then the user-supplied override takes precedence over the built-in override. User-defined overrides may call built-in overrides.
A complete list can be found on the page on built-in overrides.
Overrides and forward declarations
It is possible for user-defined overrides to have forward declarations to
other functions. For example, this override defines a id_ptr2 function, which
invokes a forward declaration to id_ptr:
(declare @id_ptr ((p (Ptr 64))) (Ptr 64))
(defun @id_ptr2 ((p (Ptr 64))) (Ptr 64)
(start start:
(let res (funcall @id_ptr p))
(return res)))
This id_ptr2 override can then be combined with the id_ptr override above
like so:
grease prog.bc --overrides id_ptr.llvm.cbl --overrides id_ptr2.llvm.cbl
grease will ensure that the forward declaration to id_ptr is resolved to
the public function of the same name. If grease cannot find a public function
for an override named id_ptr, then grease will raise an error.
Overrides YAML files
In addition to specifying function overrides by name via the --overrides
flag, grease also supports specifying function overrides by address via the
--overrides-yaml <FILE>.yaml flag. <FILE>.yaml should be a YAML file with
the following schema:
function address overrides:
ADDR_1: "NAME_1"
...
ADDR_n: "NAME_n"
Whenever grease calls a function at one of the ADDR_i addresses, it will
resolve the function to the override with the name NAME_i. Two examples of
scenarios where you may want to use this feature:
-
Stripped binaries lack function symbols, which makes it impossible to associate function overrides to names in the binary. As such, the only way to specify overrides for stripped binaries is to use
--overrides-yaml. -
Let's suppose you want to create an override for a built-in function such as
malloc, except that you want your override to do something slightly different from the default override thatgreaseuses. We could image a version ofmallocthat prints a message whenever it is called:; The built-in override for malloc (declare @malloc ((size (Bitvector 64))) (Ptr 64)) ; The custom version of malloc, which prints a message (defun @chatty_malloc ((size (Bitvector 64))) (Ptr 64) (start start: (println "Calling malloc!") (let ptr (funcall @malloc size)) (return ptr)))Passing
--overrides chatty_malloc.x86.cblwon't work, however, since the name of the function in the binary ismalloc, notchatty_malloc. Nor would it work to renamechatty_malloctomalloc, as that name would clash with the built-in override, which we need to use in the implementation of the custom override.Overrides YAML files offer a solution to this problem. We can pass
--overrides-yaml overrides.yamltogrease, where the contents ofoverrides.yamllook something like this:function address overrides: 0x1234: "malloc" # Assume that malloc's address is 0x1234
If you specify an override for a function f via --overrides and also for
f's address via --overrides-yaml, then the address override will take
precedence.
Startup overrides
Startup overrides are a special form of override that runs before the execution
of an entrypoint function. A startup override can be thought of as overriding
the part of grease that creates the initial arguments that are passed to the
entrypoint function before simulating it. While grease's default heuristics
can often figure out the right argument values to pass to the function, there
are times when it can be convenient to have finer-grained control over this
process. Some examples:
-
Triggering a bug requires an extremely large memory allocation. For instance, imagine that a bug is only triggered when a pointer argument points to an allocation of size
2^^64bytes in size. Becausegrease's default heuristics increase the size of allocations one byte at a time, agreaseuser would have a wait a very long time in order for the heuristics to discover that the memory allocation must be of size2^^64(assuming thatgreasedoes not time out or trigger its recursion limit before then). -
Triggering a bug requires multiple arguments to be related to each other in a way that is not captured by
grease's heuristics. For example, it is somewhat commonplace for C functions to pass pairs of arguments where one argument is a buffer (call itbuf) and another argument is the size ofbuf(call itbuf_sz). One would expect that the size of the allocation thatbufpoints to would always be equal tobuf_sz, butgrease's heuristics do not guarantee this property:greaseis liable to increase the size ofbufin a way that does not respect the value ofbuf_sz.
In such scenarios, it can be helpful to use a startup override to carefully
dictate what the initial arguments to the function should be. To do so, one can
use the --symbol-startup-override SYMBOL:FILE or --address-startup-override ADDR:FILE command-line arguments. These are like --symbol and --address,
respectively, except that they each take an additional FILE argument
(separated from the function symbol or address by a : character) representing
the path to the startup override file.
Like other forms of overrides, startup overrides are expected to be written in Crucible S-expression syntax. They must also adhere to the following constraints:
-
There must be a function named "
startup" contained in the file. Thestartupfunction will be invoked at startup right before invoking the entrypoint function with the argument values that the startup override produces. -
The type of the
startupfunction has very particular requirements:-
If the input program is a binary or a Macaw S-expression program, then
startupmust take a register struct as input and return a register struct as output. For example, on x86-64 the argument and result type must beX86Regs. -
If the input program is LLVM bitcode or an LLVM S-expression program, then
startupmust take the same argument types as the entrypoint function, and it must return a struct containing the same argument types. For example, if the entrypoint function is an LLVM function with the type signaturei8 foo(i16, i32), then the startup override must have the type(defun @startup ((x (Ptr 16)) (y (Ptr 32))) (Struct (Ptr 16) (Ptr 32)) ...).
-
In both cases, the arguments to the startup override consist of the "default"
initial arguments that grease would normally pass directly to the
entrypoint function, and the return value is what will actually be passed
to the entrypoint function.
Note that:
-
Unlike other forms of overrides, startup overrides do not require their file paths to have particular naming conventions.
-
Just like how the entrypoint function can be invoked multiple times during the refinement process, the startup override can also be invoked multiple times during refinement. As a result, it is possible for the startup override to be supplied different arguments each time it is is invoked during refinement.
Address overrides
Users may supply address overrides via --addr-override. Address overrides
are overrides that run when symbolic execution reaches a particular address
(i.e., instruction pointer value). Address overrides are only available when
executing binaries. Address overrides follow the file and function naming
conventions described above.
An address override takes the register struct (e.g., X86Regs) as an input
and returns Unit. When control reaches the address in question, the override
will be passed the current contents of the registers.
Address overrides are subject to a few limitations:
- They must terminate and return a total result, or they must abort.
- They may not modify memory.
The S-expression language
This page describes how GREASE uses the the Crucible S-expression language. There are two ways that GREASE interacts with this language:
- Users can provide overrides written in it.
- Developers can write test-cases in it, see S-expression programs.
Each language supported by GREASE extends the base S-expression language with additional types and operations, see:
- macaw-symbolic-syntax for binaries
- macaw-aarch32-syntax for AArch32
- macaw-ppc-syntax for PowerPC
- macaw-x86-syntax for x86_64
- crucible-llvm-syntax for LLVM
S-expression-specific overrides
There are a few overrides that are only available in S-expression files (programs or overrides).
Concretization overrides
GREASE provides two kinds of concretization overrides:
Unsound concretization (conc-*): Makes 1 solver query to get a concrete
value. Fast but unsound for verification; picks an arbitrary value when
multiple solutions exist.
Sound (unique) concretization (unique-conc-*): Makes 2 solver queries to
check if the value has exactly one possible model. If unique, concretizes;
otherwise returns the symbolic value unchanged. Sound for verification.
(declare @conc-bool ((b Bool)) Bool)
(declare @conc-bv-8 ((bv (Bitvector 8))) (Bitvector 8))
(declare @conc-bv-16 ((bv (Bitvector 16))) (Bitvector 16))
(declare @conc-bv-32 ((bv (Bitvector 32))) (Bitvector 32))
(declare @conc-bv-64 ((bv (Bitvector 64))) (Bitvector 64))
(declare @conc-integer ((i Integer)) Integer)
(declare @conc-nat ((n Nat)) Nat)
(declare @conc-ptr-32 ((p (Ptr 32))) (Ptr 32))
(declare @conc-ptr-64 ((p (Ptr 64))) (Ptr 64))
(declare @conc-vector-bv-8 ((v (Vector (Bitvector 8)))) (Vector (Bitvector 8)))
(declare @conc-vector-bv-16 ((v (Vector (Bitvector 16)))) (Vector (Bitvector 16)))
(declare @conc-vector-bv-32 ((v (Vector (Bitvector 32)))) (Vector (Bitvector 32)))
(declare @conc-vector-bv-64 ((v (Vector (Bitvector 64)))) (Vector (Bitvector 64)))
(declare @unique-conc-bool ((b Bool)) Bool)
(declare @unique-conc-bv-8 ((bv (Bitvector 8))) (Bitvector 8))
(declare @unique-conc-bv-16 ((bv (Bitvector 16))) (Bitvector 16))
(declare @unique-conc-bv-32 ((bv (Bitvector 32))) (Bitvector 32))
(declare @unique-conc-bv-64 ((bv (Bitvector 64))) (Bitvector 64))
(declare @unique-conc-integer ((i Integer)) Integer)
(declare @unique-conc-nat ((n Nat)) Nat)
(declare @unique-conc-ptr-32 ((p (Ptr 32))) (Ptr 32))
(declare @unique-conc-ptr-64 ((p (Ptr 64))) (Ptr 64))
(declare @unique-conc-vector-bv-8 ((v (Vector (Bitvector 8)))) (Vector (Bitvector 8)))
(declare @unique-conc-vector-bv-16 ((v (Vector (Bitvector 16)))) (Vector (Bitvector 16)))
(declare @unique-conc-vector-bv-32 ((v (Vector (Bitvector 32)))) (Vector (Bitvector 32)))
(declare @unique-conc-vector-bv-64 ((v (Vector (Bitvector 64)))) (Vector (Bitvector 64)))
@conc-bool, @conc-integer, @conc-nat, @conc-bv-*
These overrides request a model from the SMT solver and return the concrete value of the input in the model.
@unique-conc-bool, @unique-conc-integer, @unique-conc-nat, @unique-conc-bv-*
These overrides check if the value has a unique concrete value across all satisfying models. If unique, returns the concrete value; otherwise returns the symbolic value unchanged.
@conc-ptr-*
These overrides request a model from the SMT solver and return a pointer with both the block number and offset concretized in the same model.
@unique-conc-ptr-*
These overrides check if the pointer has a unique block number and offset across all satisfying models. If unique, returns the concrete pointer; otherwise returns the symbolic pointer unchanged.
@conc-vector-bv-*
These overrides request a model from the SMT solver and return a vector where all bitvector elements have been concretized in the same model. This ensures consistency across all elements of the vector.
@unique-conc-vector-bv-*
These overrides check if all elements of the vector have unique concrete values across all satisfying models. If all elements are uniquely determined, returns the concrete vector; otherwise returns the symbolic vector unchanged.
@fresh-bytes and @write-byte-vec
The bytes created using fresh-bytes will be concretized and printed to
the terminal if GREASE finds a possible bug. In contrast to @write-bytes,
@write-byte-vec does not add a null terminator.
fresh-bytes and write-byte-vec can be combined to create overrides for
functions that do I/O, such as the following basic override for recv, shown
for x86_64 and LLVM:
; Basic x86_64 override for `recv`.
;
; Ignores `socket` and `flags`, always reads exactly `length` bytes.
(declare @fresh-bytes ((name (String Unicode)) (num (Bitvector 64))) (Vector (Bitvector 8)))
(declare @write-byte-vec ((dest (Ptr 64)) (src (Vector (Bitvector 8)))) Unit)
; `man 2 recv`: ssize_t recv(int socket, void *buffer, size_t length, int flags)
(defun @recv ((socket (Ptr 64)) (buffer (Ptr 64)) (length (Ptr 64)) (flags (Ptr 64))) (Ptr 64)
(start start:
(let length-bv (pointer-to-bits length))
(let bytes (funcall @fresh-bytes "recv" length-bv))
(funcall @write-byte-vec buffer bytes)
(return length)))
; Basic LLVM override for `recv`.
;
; Ignores `socket` and `flags`. Always reads exactly `length` bytes.
(declare @fresh-bytes ((name (String Unicode)) (num (Bitvector 64))) (Vector (Bitvector 8)))
(declare @write-byte-vec ((dest (Ptr 64)) (src (Vector (Bitvector 8)))) Unit)
; `man 2 recv`: ssize_t recv(int socket, void *buffer, size_t length, int flags)
(defun @recv ((socket (Ptr 32)) (buffer (Ptr 64)) (length (Ptr 64)) (flags (Ptr 32))) (Ptr 64)
(start start:
(let length-bv (ptr-offset 64 length))
(let bytes (funcall @fresh-bytes "recv" length-bv))
(funcall @write-byte-vec buffer bytes)
(return length)))
fresh-bytes returns the bytes as a Vector (Bitvector 8), which can be
inspected or manipulated before being passed to write-byte-vec.
LLVM-specific overrides
For LLVM S-expression files (programs or overrides), the following overrides are also available:
(declare @read-bytes ((x (Ptr 64))) (Vector (Bitvector 8)))
(declare @read-c-string ((x (Ptr 64))) (String Unicode)) (declare @write-bytes
((dest (Ptr 64)) (src (Vector (Bitvector 8)))) Unit)`@write-byte-vec` does *not*
add a null terminator.
(declare @write-c-string ((dst (Ptr 64)) (src (String Unicode))) Unit)
See the upstream documentation.
Debugging
This is a guide to debugging the results of GREASE and Screach.
It is meant to be suitable for consumption by both human and coding agents.
Hangs and timeouts
Symbolic reads and writes
The GREASE/Screach memory model can struggle with
unconstrained symbolic reads. Try running with -v to check which instructions
are being executed. If you see GREASE/Screach hanging on a load or store, e.g.,
Executing instruction at 0x10a9f972: sub rcx,QWORD PTR [r14+0x8]
then the pointer might be symbolic/unconstrained.
To diagnose the problem, you can try using --debug{,-cmd} with break/step N/mreg to inspect the values of the registers at that program point.
To fix the issue, you can try:
- Passing
--arg-buf-init,--arg-u64, or similar flags to specify initial values for registers - Creating an
--initial-preconditionto partially specify the values of registers and the contents of memory - Creating a startup override to partially specify the values of register and the contents of memory
- Running from a caller of the function under analysis, which may set the registers/memory to values that are more constrained than GREASE's default initial precondition
Exploring unrelated code
By default, GREASE and Screach execute each function that is called. You may find that symbolic execution enters, explores, and perhaps even errors out in code that is along or adjacent to paths of interest, but is not itself the focus of your analysis.
To diagnose the problem, you can try:
- Running with
-vto see executed function calls and instructions - Using
--debug{,-cmd}withbreak/step N/btto inspect the call stack and see if you're deep into uninteresting code
To fix the issue, you can try:
- Passing
--skipto skip calls to irrelevant functions - Using
--arg-*,--initial-precondition, etc. to avoid taking conditional branches that explore those paths - Creating a simplified model (i.e., an override) of the irrelevant code
- Passing
--avoidto Screach
Errors
Unsupported instructions
GREASE or Screach might bail on unrecognized instructions:
Goal failed:
0x7db711ab138a: error: in 0x7db711ab1380
0x7db711ab138f: Could not decode instruction c4e268f5
<no details available>
These are especially common for vectorized instructions, often in libc code
(e.g., for memcpy/memmove or similar).
To fix the issue, you can try all of the same steps in "Exploring unrelated code" above.
Built-in overrides
In addition to user-defined overrides, GREASE also provides a number of built-in overrides that are built directly into the tool. Many of the built-in overrides correspond to functions from libc. For various reasons, these overrides are not defined using S-expression syntax. Unlike user-defined overrides, these overrides are always enabled by default, without needing the user to explicitly enable them.
If a user supplies an override of the same name as a built-in override, then the user-supplied override takes precedence over the built-in override. User-defined overrides may call built-in overrides.
The list of built-in overrides
The following is a complete list of built-in overrides, given with C-like type signatures.
i8* @memcpy( i8*, i8*, size_t )i8* @__memcpy_chk ( i8*, i8*, size_t, size_t )i8* @memmove( i8*, i8*, size_t )i8* @memset( i8*, i32, size_t )i8* @__memset_chk( i8*, i32, size_t, size_t )i8* @calloc( size_t, size_t )i8* @realloc( i8*, size_t )i8* @malloc( size_t )i32 @posix_memalign( i8**, size_t, size_t )void @free( i8* )i32 @printf( i8*, ... )i32 @__printf_chk( i32, i8*, ... )i32 @putchar( i32 )i32 @puts( i8* )size_t @strlen( i8* )double @ceil( double )float @ceilf( float )double @floor( double )float @floorf( float )float @fmaf( float, float, float )double @fma( double, double, double )i32 @isinf( double )i32 @__isinf( double )i32 @__isinff( float )i32 @isnan( double )i32 @__isnan( double )i32 @__isnanf( float )i32 @__isnand( double )double @sqrt( double )float @sqrtf( float )double @sin( double )float @sinf( float )double @cos( double )float @cosf( float )double @tan( double )float @tanf( float )double @asin( double )float @asinf( float )double @acos( double )float @acosf( float )double @atan( double )float @atanf( float )double @sinh( double )float @sinhf( float )double @cosh( double )float @coshf( float )double @tanh( double )float @tanhf( float )double @asinh( double )float @asinhf( float )double @acosh( double )float @acoshf( float )double @atanh( double )float @atanhf( float )double @hypot( double, double )float @hypotf( float, float )double @atan2( double, double )float @atan2f( float, float )float @powf( float, float )double @pow( double, double )double @exp( double )float @expf( float )double @log( double )float @logf( float )double @expm1( double )float @expm1f( float )double @log1p( double )float @log1pf( float )double @exp2( double )float @exp2f( float )double @log2( double )float @log2f( float )double @exp10( double )float @exp10f( float )double @__exp10( double )float @__exp10f( float )double @log10( double )float @log10f( float )void @__assert_rtn( i8*, i8*, i32, i8* )void @__assert_fail( i8*, i8*, i32, i8* )void @abort()void @exit( i32 )i8* @getenv( i8* )i32 @htonl( i32 )i16 @htons( i16 )i32 @ntohl( i32 )i16 @ntohs( i16 )i32 @abs( i32 )i32 @labs( i32 )i64 @labs( i64 )i64 @llabs( i64 )i32 @__cxa_atexit( void (i8*)*, i8*, i8* )i32 @open( i8*, i32 )i32 @close( i32 )ssize_t @read( i32, i8*, size_t )ssize_t @write( i32, i8*, size_t )
LLVM-specific overrides
For LLVM programs (but not binaries), the following built-in overrides are also available:
void @llvm.lifetime.start( i64, i8* )void @llvm.lifetime.end( i64, i8* )void @llvm.assume ( i1 )void @llvm.trap()void @llvm.ubsantrap( i8 )i8* @llvm.stacksave()void @llvm.stackrestore( i8* )void @llvm.memmove.p0i8.p0i8.i32( i8*, i8*, i32, i32, i1 )void @llvm.memmove.p0i8.p0i8.i32( i8*, i8*, i32, i1 )void @llvm.memmove.p0.p0.i32( ptr, ptr, i32, i1 )void @llvm.memmove.p0i8.p0i8.i64( i8*, i8*, i64, i32, i1 )void @llvm.memmove.p0i8.p0i8.i64( i8*, i8*, i64, i1 )void @llvm.memmove.p0.p0.i64( ptr, ptr, i64, i1 )void @llvm.memset.p0i8.i64( i8*, i8, i64, i32, i1 )void @llvm.memset.p0i8.i64( i8*, i8, i64, i1 )void @llvm.memset.p0.i64( ptr, i8, i64, i1 )void @llvm.memset.p0i8.i32( i8*, i8, i32, i32, i1 )void @llvm.memset.p0i8.i32( i8*, i8, i32, i1 )void @llvm.memset.p0.i32( ptr, i8, i32, i1 )void @llvm.memcpy.p0i8.p0i8.i32( i8*, i8*, i32, i32, i1 )void @llvm.memcpy.p0i8.p0i8.i32( i8*, i8*, i32, i1 )void @llvm.memcpy.p0.p0.i32( ptr, ptr, i32, i1 )void @llvm.memcpy.p0i8.p0i8.i64( i8*, i8*, i64, i32, i1 )void @llvm.memcpy.p0i8.p0i8.i64( i8*, i8*, i64, i1 )void @llvm.memcpy.p0.p0.i64( ptr, ptr, i64, i1 )i32 @llvm.objectsize.i32.p0i8( i8*, i1 )i32 @llvm.objectsize.i32.p0i8( i8*, i1, i1 )i32 @llvm.objectsize.i32.p0i8( i8*, i1, i1, i1 )i32 @llvm.objectsize.i32.p0( ptr, i1, i1, i1 )i64 @llvm.objectsize.i64.p0i8( i8*, i1 )i64 @llvm.objectsize.i64.p0i8( i8*, i1, i1 )i64 @llvm.objectsize.i64.p0i8( i8*, i1, i1, i1 )i64 @llvm.objectsize.i64.p0( ptr, i1, i1, i1 )void @llvm.prefetch.p0i8( i8*, i32, i32, i32 )void @llvm.prefetch.p0( ptr, i32, i32, i32 )void @llvm.prefetch( i8*, i32, i32, i32 )float @llvm.copysign.f32( float, float )double @llvm.copysign.f64( double, double )float @llvm.fabs.f32( float )double @llvm.fabs.f64( double )float @llvm.ceil.f32( float )double @llvm.ceil.f64( double )float @llvm.floor.f32( float )double @llvm.floor.f64( double )float @llvm.sqrt.f32( float )double @llvm.sqrt.f64( double )float @llvm.sin.f32( float )double @llvm.sin.f64( double )float @llvm.cos.f32( float )double @llvm.cos.f64( double )float @llvm.pow.f32( float, float )double @llvm.pow.f64( double, double )float @llvm.exp.f32( float )double @llvm.exp.f64( double )float @llvm.log.f32( float )double @llvm.log.f64( double )float @llvm.exp2.f32( float )double @llvm.exp2.f64( double )float @llvm.log2.f32( float )double @llvm.log2.f64( double )float @llvm.log10.f32( float )double @llvm.log10.f64( double )i1 @llvm.is.fpclass.f32( float, i32 )i1 @llvm.is.fpclass.f64( double, i32 )float @llvm.fma.f32( float, float, float )double @llvm.fma.f64( double, double, double )float @llvm.fmuladd.f32( float, float, float )double @llvm.fmuladd.f64( double, double, double )<2 x i64> @llvm.x86.pclmulqdq(<2 x i64>, <2 x i64>, i8)void @llvm.x86.sse2.storeu.dq( i8*, <16 x i8> )
Binary-specific overrides
For binaries (but not LLVM programs), the following built-in overrides are also available:
void @__stack_chk_fail()void @__stack_chk_fail_local()i32 @sscanf( i8*, i8*, ... )i32 @__isoc99_sscanf( i8*, i8*, ... )
S-expression-specific overrides
The following overrides are only available in S-expression files (programs or overrides). See The S-expression language for more details.
(declare @conc-bool ((b Bool)) Bool)
(declare @conc-bv-8 ((bv (Bitvector 8))) (Bitvector 8))
(declare @conc-bv-16 ((bv (Bitvector 16))) (Bitvector 16))
(declare @conc-bv-32 ((bv (Bitvector 32))) (Bitvector 32))
(declare @conc-bv-64 ((bv (Bitvector 64))) (Bitvector 64))
(declare @conc-integer ((i Integer)) Integer)
(declare @conc-nat ((n Nat)) Nat)
(declare @conc-ptr-32 ((p (Ptr 32))) (Ptr 32))
(declare @conc-ptr-64 ((p (Ptr 64))) (Ptr 64))
(declare @conc-vector-bv-8 ((v (Vector (Bitvector 8)))) (Vector (Bitvector 8)))
(declare @conc-vector-bv-16 ((v (Vector (Bitvector 16)))) (Vector (Bitvector 16)))
(declare @conc-vector-bv-32 ((v (Vector (Bitvector 32)))) (Vector (Bitvector 32)))
(declare @conc-vector-bv-64 ((v (Vector (Bitvector 64)))) (Vector (Bitvector 64)))
(declare @unique-conc-bool ((b Bool)) Bool)
(declare @unique-conc-bv-8 ((bv (Bitvector 8))) (Bitvector 8))
(declare @unique-conc-bv-16 ((bv (Bitvector 16))) (Bitvector 16))
(declare @unique-conc-bv-32 ((bv (Bitvector 32))) (Bitvector 32))
(declare @unique-conc-bv-64 ((bv (Bitvector 64))) (Bitvector 64))
(declare @unique-conc-integer ((i Integer)) Integer)
(declare @unique-conc-nat ((n Nat)) Nat)
(declare @unique-conc-ptr-32 ((p (Ptr 32))) (Ptr 32))
(declare @unique-conc-ptr-64 ((p (Ptr 64))) (Ptr 64))
(declare @unique-conc-vector-bv-8 ((v (Vector (Bitvector 8)))) (Vector (Bitvector 8)))
(declare @unique-conc-vector-bv-16 ((v (Vector (Bitvector 16)))) (Vector (Bitvector 16)))
(declare @unique-conc-vector-bv-32 ((v (Vector (Bitvector 32)))) (Vector (Bitvector 32)))
(declare @unique-conc-vector-bv-64 ((v (Vector (Bitvector 64)))) (Vector (Bitvector 64)))
(declare @fresh-bytes ((name (String Unicode)) (num (Bitvector w))) (Vector (Bitvector 8)))
(declare @write-byte-vec ((dest (Ptr w)) (src (Vector (Bitvector 8)))) Unit)
For LLVM S-expression files (programs or overrides), the following overrides are also available:
(declare @read-bytes ((x (Ptr 64))) (Vector (Bitvector 8)))
(declare @read-c-string ((x (Ptr 64))) (String Unicode))
(declare @write-bytes ((dest (Ptr 64)) (src (Vector (Bitvector 8)))) Unit)
(declare @write-c-string ((dst (Ptr 64)) (src (String Unicode))) Unit)
Discussion
The following overrides merit a bit of discussion:
-
accept,bind,connect,listen,recv,send, andsocket: see I/O -
abortTerminate
greaseby raising an error. Note that this termination is immediate, sogreasewill not attempt to detect issues in any code following the call toabort. -
freeFree a pointer that was allocated using
malloc. -
mallocAllocate a fresh pointer of the given size in the underlying memory model. This pointer is assumed not to alias with any pointers allocated by previous calls to
malloc. -
open,close,read, andwriteSee I/O.
-
sscanfand__isoc99_sscanfParse formatted input from a string. Both the input string and the format string must be concrete (not symbolic). Supported conversion specifiers include
%d,%c,%s,%x,%f,%p,%n, and%[...](character sets, e.g.,%[abc]or%[^abc]). Length modifiershh,h,l,ll,L,j,t, andzare supported. Maximum width is only respected for string-like conversions (e.g.,%5s). Character set ranges (e.g.,%[0-9]) and character sets that include the]character (e.g.,%[]]) are not supported.
Crucible types for overrides
The types in the list above represent Crucible types according to the following schema:
double:(FP Double)float:(FP Float)i<N>:(Ptr <N>)<<LANES> x i<N>>: (there is no syntax for this Crucible type)ptr:(Ptr <word-size>)size_t:(Ptr <word-size>)ssize_t:(Ptr <word-size>)<T>*:(Ptr <word-size>)void:Unit
where <word-size> is:
- 32 for AArch32
- 64 for LLVM
- 32 for PPC32
- 64 for PPC64
- 64 for x86_64
Comparison with other tools and frameworks
This page situates GREASE in the landscape of similar program analysis tools. These comparisons mostly aim to highlight which tools might be relevant for a given use-case rather than provide apples-to-apples comparisons of similar features. We have limited experience with (and correspondingly, limited understanding of) many of the tools listed here.
| Tool | Binary | Source Code/LLVM | Available Under-constrained Algorithm | Open Source |
|---|---|---|---|---|
| angr | Yes | No* | Yes1 | Yes |
| GREASE | Yes | Yes | Yes | Yes |
| KLEE | No2 | Yes | No | Yes |
| UC-KLEE | No | Yes | Yes | No |
| UC-Crux | No | Yes | Yes | Yes |
| Macaw | Yes | No | No | Yes |
GREASE focuses on providing an out-of-the-box under-constrained symbolic execution tool that allows analysts to find and fix bugs. The tool provides a command line interface that allows engineers to directly symbolically execute arbitrary functions within a target binary or LLVM program and find bugs. This capability arises from a focus on scalable and relatively automated techniques (under-constrained symbolic execution), and the use of a generic symbolic execution framework and memory model that enables support for both binaries and LLVM programs, and wrapping these capabilities in an easy to use interface.
Below we highlight some general categories of tools that offer points of comparison.
-
Binary analysis frameworks: angr, Macaw, BAP, and binsec. These frameworks are typically libraries that provide core binary analysis capabilities. Example capabilities include disassembly, control flow recovery, lifting and simplification, variable recovery, and type inference. Frameworks often include symbolic semantics for some intermediate representation. Macaw and angr both support forward symbolic execution of binaries from an entrypoint. This approach on its own suffers from path explosion in complex programs, typically requiring the user to configure the analysis in some way for programs of moderate scale. In binary analysis frameworks, this configuration is typically done by configuring the library manually with some interesting state and direction which requires expert analysis. These frameworks are also limited to performing analysis directly on a binary, preventing these tools from taking advantage of additional structure provided by source code (for instance types and segmented memory models). These frameworks, however, are a key component of building a tool like GREASE that can perform underconstrained symbolic execution on binaries. GREASE uses Macaw as the underlying binary analysis framework, which handles code recovery and symbolic semantics.
-
Source analyzers/symbolic execution engines: KLEE performs forward symbolic execution on LLVM bitcode. Compared to binary analysis tools, performing analysis on LLVM IR allows KLEE to use more efficient memory models that split memory into separate abstract objects. Unfortunately, the tight integration of KLEE with LLVM means that KLEE cannot perform analysis on binaries. The tool also suffers from path explosion on large programs when exploring from an entrypoint.
-
Source-level under-constrained symbolic execution engines: UC-Crux and UC-KLEE perform under-constrained symbolic execution on LLVM IR, enabling automated symbolic execution of arbitrary functions within a target binary with minimal configuration. Due to the use of LLVM, these tools are limited to programs where the source code is available and can be compiled to LLVM bitcode or a whole program lifting to LLVM.
-
Fuzzers: Fuzzers like AFL, AFL++, and LibAFL exercise a program by generating random inputs targeting a given harness. An advantage of fuzzers is that they provide concrete inputs that trigger a given bug from defined harnesses. Sufficiently constrained harnesses are less likely to report false positives than under-constrained symbolic execution. Fuzzers also can sometimes explore deeper paths (with less breadth) than symbolic execution given precise seed inputs, because concrete inputs limit fanout. Unfortunately, using fuzzers requires defining a harness that transforms bytes into valid input for a target function. Lack of sufficiently broad fuzzing harnesses is often a constraining factor in project coverage. Under-constrained symbolic execution, on the other hand, can be targeted at an arbitrary function in a target program without prior configuration. The inferred preconditions effectively act as an automatically generated harness for the target function. Additionally, symbolic execution can achieve greater breadth by directly exploring and solving for paths that fuzzers would struggle to generate random inputs for (e.g. specific strings or arithmetic checks). Specialized fuzzing techniques can help fuzzers discover inputs that exercise hard to reach paths (e.g. TraceCMP), however, in general many complex branch conditions can block fuzzers.
angr has some support for JVM bytecode although the extent of support is unclear. Similarly there is a UNDER_CONSTRAINED_SYMEXEC option that populates unbound pointers with a fresh region sufficient for the load it is unclear how well this interacts with angr's concretizing memory model (e.g. pointers to regions with pointers etc)
Binary to LLVM lifters do exist allowing some tooling which targets LLVM bitcode to be applied to binaries even when source is not available. As an example KLEE-Native emulates the binary via liftings provided by remill. These liftings are low-level and typically lose efficiencies provided by high-level representations like abstract memory locations.
Function calls
GREASE's algorithm for handling function calls is as follows:
- If the call is through a symbolic function pointer, then:
- If
--error-symbolic-fun-callswas provided, an error is generated. - Otherwise, the call is skipped.
- If
- Otherwise, the virtual address is resolved to an address in the binary. If
this fails:
- If
--skip-invalid-call-addrswas provided, the call is skipped. - Otherwise, an error is generated.
- If
- Once GREASE has an address in the binary, it checks if the address corresponds
to the beginning of a function.
- If so,
- If the function was passed to
--skip, the call is skipped. - Otherwise, the function is symbolically executed.
- If the function was passed to
- If not, GREASE checks if the address corresponds to a PLT stub.
- If so, GREASE checks if it has an override for that function. If so, the override is executed. If not, the call is skipped.
- If the address was not the beginning of a function and was not a PLT stub, then the call is skipped.
- If so,
No registers or memory are havoc'd if a function call is skipped (though this may change in the future).
I/O
Overrides
GREASE provides built-in overrides for the I/O primitives open,
close, read, and write.
These overrides leverage Crucible's experimental symbolic I/O capabilities. In
particular, these overrides require the use of a symbolic filesystem, which must
be specified with --fs-root <path-to-filesystem-root> when invoking grease.
See symbolic I/O for a more detailed description of what the contents of the
symbolic filesystem should look like.
Standard streams
GREASE attempts to provide a POSIX environment. In particular, when in use,
the [standard streams] stdin, stdout, and stderr are mapped to file
descriptors 0, 1, and 2 respectively. stdin is empty by default, though
--sym-stdin N populates it with N symbolic bytes. stdout and stderr do
not exist by default and their file descriptors may be reused, e.g., by open.
If their content is specified via --fs-root, then they will have their usual
file descriptor numbers.
Sockets and networking
GREASE provides basic overrides for the following socket I/O functions:
acceptbindconnectlistenrecvsendsocket
These overrides are quite limited.
- For successful execution, GREASE must execute the entire
"chain" of socket-related function calls, e.g., for a server,
socket/bind/listen/accept/recv. If GREASE only executes a suffix of the chain, execution will fail. - Opening different sockets in different branches of execution is not supported.
- The socket domain, type, and path (for
AF_UNIXsockets) or port number (forAF_INET{6}sockets) must all be concrete. - Only domains
AF_UNIX,AF_INET, andAF_INET6are supported. - Only socket types
SOCK_STREAM,SOCK_DGRAM, andSOCK_SEQPACKETare supported. - Reading from sockets requires setting their contents in the symbolic filesystem in advance. (See GREASE's test suite for an example.)
acceptignores theaddrandaddrlenparameters.
Limitations
GREASE is subject to a variety of limitations. They can be characterized according to several criteria:
- Are the issues fundamental, i.e., inherent to the overall approach? Or are they incidental, and could be solved given enough engineering?
- Are they threats to correctness, i.e., could they induce GREASE to report a falsehood?
- Are they threats to completeness, i.e., could they cause GREASE to fail to analyze (part of) a given program, or to only analyze part of its behavior?
The following table characterizes several of GREASE's limitations, which are described in more detail below.
| Limitation | Fundamental | Correctness | Completeness |
|---|---|---|---|
| Path explosion | Y | N | Y |
| k-bounding | Y | N | Y |
| External code | Y | Y | Y |
| Scalability of SMT | Y | N | Y |
| Analyzing binaries | Y | Y | N |
| Aliasing | N | Y | Y |
| Code discovery | N | N | Y |
| Heuristics | N | Y | Y |
| Features of binaries | N | N | Y |
| Quirks of machine code | N | N | Y |
Fundamental limitations
The limitations described in this section are fundamental to GREASE's analysis, and are rooted in theorems in computability and complexity theory. No amount of engineering effort could result in fully general, automated solutions to these problems. However, real progress can be made by introducing heuristics for common cases, or resorting to human insight and input.
Path explosion
Like many program analyses, GREASE suffers from the path explosion problem:
path explosion is a fundamental problem that limits the scalability and/or completeness of certain kinds of program analyses, including fuzzing, symbolic execution, and path-sensitive static analysis. Path explosion refers to the fact that the number of control-flow paths in a program grows exponentially ("explodes") with an increase in program size and can even be infinite in the case of programs with unbounded loop iterations. Therefore, any program analysis that attempts to explore control-flow paths through a program will [...] have exponential runtime in the length of the program1
https://en.wikipedia.org/wiki/Path_explosion
GREASE's under-constrained symbolic execution (uc-symex) attempts to mitigate the impact of path explosion relative to traditional symbolic execution (symex). By starting at an arbitrary function (instead of only at main, as in traditional symex), GREASE can achieve higher coverage of the program under analysis. However, uc-symex is still subject to path explosion: it still involves exploring all control-flow paths that start at the function under analysis. In the limit (i.e., when analyzing main), this can boil down to the same problem as in traditional symex.
In practice, this means that GREASE may report a timeout when analyzing functions with complex control-flow (or functions that call such functions).
k-bounding
GREASE uses a sophisticated, bit-precise memory model with support for advanced features such as reads, writes, and copies of symbolic data with symbolic sizes, to and from symbolic pointers. However, this memory model can't express unbounded heap data-structures. For example, GREASE can't determine the behavior of a function when fed a linked list of arbitrary length, it can only analyze the behavior on linked lists with symbolic content but some fixed length. In practice, GREASE examines program behavior up to some maximum bound, an approach known in static analysis as k-bounding. The program features subject to k-bounding include data structures, loop iterations, and recursion.
Practically speaking, GREASE may report that the bound k has been exceeded when analyzing complex functions. Users may set the bound k at the command-line.
External code
Programs are not pure functions; they interact with the world. They call external libraries, interact with the kernel via syscalls, and query and manipulate with hardware devices. Not only is it infeasible to precisely model the plethora of complex systems with which a program under analysis might interface, given the precision of GREASE's analysis, it is often impractical to even soundly over- or under-approximate the behaviors of such systems.
GREASE provides precise models for a wide variety of commonly used library functions (e.g., from libc) and a limited set of Linux syscalls. However, there will always be many more that cannot be analyzed. GREASE skips such calls by default, but the user may also provide their own models where necessary in the form of overrides.
Scalability of SMT
Symbolic execution fundamentally relies on SMT solvers. Despite decades of incredible research and engineering effort, the performance of such solvers remains unpredictable from problem to problem. At Galois, we've seen performance degrade especially when reasoning about programs with heavy use of floating-point values, non-linear arithmetic, and certain patterns of memory usage.2 To mitigate these difficulties, GREASE allows users to select among many SMT solvers.
If the SMT solver fails to answer a query, GREASE reports this as a timeout and doesn't offer further results for that function.
In addition to these practical limitations, there’s also a more fundamental issue: SMT solvers are built to solve an NP-hard problem. Therefore, their performance can’t be uniformly good in all cases.
Analyzing binaries
GREASE operates on compiled code (binaries and LLVM). There may be bugs (e.g., undefined behavior) in the source program that the compiler has optimized away; GREASE has no means of finding such bugs. See Undefined behavior for a more detailed discussion of which undefined behaviors GREASE can check for.
Incidental limitations
The following limitations reflect the state of GREASE today, but considerable progress on them is likely possible with further engineering effort.
Aliasing
GREASE assumes that any two pointers reachable from a function's inputs (i.e., the values in registers/arguments) do not alias. It could likely be extended to consider such cases.
Code discovery
Code discovery consists of recovering control-flow graphs (CFGs) from disassembled machine code. This task is undecidable in general, challenging in practice, and amounts to an active area of research in the field of binary analysis. GREASE's approach is thus necessarily heuristic in nature, and could always be improved to support additional common idioms (e.g., different kinds of jump tables emitted by major compilers).
If the code discovery fails to recover a CFG, GREASE reports as much and doesn't offer further results for control-flow paths that reach the site of the failure.
Heuristics
Under-constrained symbolic execution (uc-symex) analyzes functions in isolation. As discussed above, this approach improves scalability as compared to traditional symex (by mitigating path explosion), but it comes with its own trade-offs. Crucially, it makes it difficult to say with certainty whether a behavior observed during analysis is feasible in practice. Any potential error encountered during analysis could either be a true bug, or an artifact of the analysis approach. Tools based on uc-symex have heuristics that attempt to maximize true positives and minimize false positives reported to the user. Such heuristics can generally be improved with additional investment.
Features of binaries
Binary analysis is hard. Executable formats, operating systems, ISAs, relocation types, and memory models proliferate. GREASE currently supports analysis of Linux ELF binaries for 32-bit ARM, PowerPC, and x86_64. Even within those categores, GREASE lacks support for:
- some types of relocations
- executing code from shared libraries
- semantics for some instructions on some architectures (e.g.,
hlton x86_64)
Quirks of machine code
It is possible for machine code to exhibit behaviors that are not possible at the level of assembly language; GREASE cannot analyze such code. For example, GREASE doesn't support:
- self-modifying code
- run-time code generation (e.g., JIT compilation)
- jumps into the "middle" of instructions
In brief
- GREASE can only analyze code in a single thread of execution, without considering side-effects from threads or processes acting in parallel.
- GREASE has limited support for string operations. For instance, calls to
strlenwill only work on concrete pointers. These operations are very difficult to handle in a performant way in full generality, as each additional character introduces a symbolic branch. - GREASE can't handle calls through non-concrete function pointers.
- GREASE has a hard time with variable-arity functions.
- GREASE cannot model heap exhaustion or overflows.
- It's difficult to detect PLT stubs.
- GREASE does not currently detect stack buffer overflows.
- GREASE does not currently support code that runs before
main, e.g., C's__attribute__ ((constructor)), ELF's.init/.ctors/.init_array, LLVM's@llvm.global_ctors, or Rust's_init. - GREASE currently does not cope well with calls to symbolic function pointers or addresses (or syscalls with symbolic numbers). GREASE's default behavior is to skip over calls to function pointers or addresses that it cannot resolve as concrete. GREASE also includes a
--error-symbolic-fun-callscommand-line option that causes GREASE to error if it attempts to invoke a symbolic function call.
Memory model
GREASE builds on the Macaw and Crucible-LLVM memory models.
Background: Crucible-LLVM
In the Crucible-LLVM memory model (permalink),
Each allocation in the memory model is completely isolated from all other allocations and has a unique block identifier. Pointers into the memory model have two components: the identifier of the block they reference and an offset into that block. Note that both the identifier and the offset can be symbolic.
Said another way, the memory model is two-dimensional: One "axis" of a
pointer determines which allocation (possibly allocations in the case of a
symbolic block identifier) it points to, and the other "axis" is the offset
within that allocation.1 For example, the null pointer is represented by
the pair (0, 0x0).

Global memory
The Macaw memory model (and so, GREASE) represents a binary's
address space as a single Crucible-LLVM allocation of size 0xffffffff.
Pointers that appear in the binary become offsets into this allocation. For
example, if the global allocation had block identifier 1, the global g
was at address 0x903278, then a load from g would become a load from the
Crucible-LLVM pointer (1, 0x903278).
Mutable globals
Mutable global variables are tricky:
- If GREASE initialized mutable global variables to their initial values or to completely symbolic values, it's possible that GREASE would report "bugs" that are infeasible in practice, because the value of the global required to trigger the bug isn't actually feasible at any of the callsites to the function under analysis.
- On the other hand, if GREASE doesn't initialize global variables at all, any loads from them (that aren't preceded by writes made by the function under analysis or its callees) will fail. As mutable global variables are pervasive, this would lead to a significant lack of coverage.
GREASE's behavior in this regard is controlled via the --globals flag. The
possible values are:
initialized: Each mutable global is initialized using its initializer before analysis of the target function.symbolic: Each mutable global is initialized to a symbolic value before analysis of the target function.uninitialized: Mutable globals are left uninitialized. Reads from mutable globals will fail, causing GREASE to be unable to proceed with analysis.
The stack
GREASE represents the stack as a separate Crucible-LLVM allocation. Before symbolically executing the target function, the stack pointer is initialized to point at the end of a fairly large allocation (currently, 1 MiB). This means that GREASE assumes a standard stack discipline, namely that the stack grows downwards from high addresses to low, and functions never access memory above their stack frame (with some exceptions, which are explained below). In theory, false positives may occur if a binary overruns this stack allocation, though in practice, symbolic execution of that much code would take a considerable amount of time.
On some architectures, GREASE will allocate a small amount of space just above the stack frame to store the current function's return address (e.g., on x86-64 and PowerPC) or the back chain (e.g., PowerPC), but otherwise, GREASE will assume that functions never access memory above their stack frame. Note that because GREASE leaves most of the space above the stack frame unallocated by default, this will cause GREASE to reject programs that load function arguments that are spilled to the stack.2 In general, it is challenging to infer how many arguments a function has from analyzing raw assembly code, so GREASE does not make an effort to do so.
Instead, GREASE offers a --stack-argument-slots=<NUM> that can be used to
allocate <NUM> additional stack slots above the stack frame before simulating
the entrypoint function. <NUM> is 0 by default, so if you know ahead of time
how many stack-spilled arguments the entrypoint function requires, you should
use --stack-argument-slots to ensure that GREASE can simulate it properly.
Note that in general, it is not advisable to run GREASE with a large
--stack-argument-slots value. This is because if GREASE reserves more stack
space than what is required to model stack-spilled arguments, then reading from
the extra stack space will succeed (incorrectly) instead of resulting in an
uninitialized stack read error (which is normally what is desired).
The heap
GREASE overrides the behavior of the malloc and free functions such that
they interact nicely with the Crucible-LLVM memory model. Each call to malloc
will generate a distinct allocation with a non-zero block identifier that is
different from all other allocations in the program, including global memory.
Similarly, each call to free will deallocate a Crucible-LLVM allocation.
Be mindful of the following limitations of GREASE's model of the heap:
- There is no limit to the maximum heap size, so GREASE cannot model heap overflows.
- Because each heap allocation is completely isolated from all other allocations, GREASE cannot model events that would arise after certain types of heap-related exploits (e.g., buffer overflows).
Non-pointer bitvectors (e.g. the 5 in int x = 5;) are represented the same way as pointers, but with a block identifier that’s concretely 0.
The number of arguments a function must have in order for it to spill some of its arguments to the stack depends on which architecture is being used. In general, the more arguments a function has, the more likely it is to spill arguments to the stack.
Refinement
Before continuing, it would be helpful to review:
- the overview
- the memory model
This page describes the refinement algorithm in additional detail. However, it does not discuss implementation techniques, which are documented in the Haddocks.
The algorithm is similar to the corresponding functionality in UC-Crux-LLVM.
The goal of the refinement loop is to discover sufficient preconditions for the successful execution of a target function. If a memory error occurs (out-of-bounds read/write, uninitialized read, etc.), the precondition is refined using heuristics, such as expanding allocations or initializing memory.
Preconditions
The preconditions are represented as a map from registers to pointer shapes. A pointer shape consists of a sequence of pointee shapes, where a pointee shape is one of:
- A number of uninitialized bytes
- A number of initialized bytes
- A pointer shape
In the initial precondition, all registers (except the instruction and stack pointers) map to an empty sequence of pointee shapes, meaning that they are not assumed to point to an allocation (i.e., they are treated as raw bitvectors).
Setting up state
Before each execution of the target function, GREASE initializes memory and registers according to the current precondition.
Memory
As described in the document on the memory model, GREASE maps the binary's address space into a single Crucible-LLVM allocation, and sets the stack pointer to the end of a separate allocation.
Registers
All registers are set to symbolic values corresponding to their shape (other than the stack and instruction pointers, which point to the end of an allocation and the beginning of the function, respectively).
For each empty pointer shape, the register is set to a fresh, symbolic value. For each non-empty pointer shape, GREASE creates a separate Crucible-LLVM allocation that is just large enough to hold all of its pointee shapes, and sets the register to a pointer to the base of that allocation. It then initializes the allocation according to the pointee shapes (which may create and initialize additional allocations, recursively).
There are a few ways to influence the initial shapes held in registers:
- Allow GREASE to use LLVM or DWARF debug info to fill them in by passing
--debug-info-types. - Provide a Shape DSL file to
--initial-precondition. - Specify initial register values with flags such as
--arg-buf-uninit. - Provide a startup override.
The later methods override the earlier ones.
The refinement loop
The refinement loop proceeds by initializing memory and registers according to the current precondition, then symbolically simulating the target function. If no error occurs, a sufficient precondition has been found and the refinement loop ends. If instead there is a memory error, the error is passed along to a series of heuristics. The heuristics generally:
- Increase the size of pointee shapes (by adding uninitialized bytes at the end)
- Turn uninitialized pointee shapes into initialized ones
- Replace (un)initialized pointee shapes with pointer shapes
These heuristics can be disabled with the --no-heuristics flag.
Rust programs
grease has experimental support for analyzing Rust programs, both when
compiled to executables and when compiled to LLVM bitcode. From a grease
perspective, the average Rust program is significantly more complicated than,
say, an average C program for a variety of reasons, including:
- Rust has a large standard library, and much of the standard library will be
included in a typical Rust program. As such,
greasehas to simulate more code on average. - Some library functions (e.g., Rust functions related to string formatting or panicking) have rather complex implementations that are difficult to symbolically execute. As such, it is often necessary to override tricky library functions to replace them with simpler implementations.
- The code that
rustcproduces often looks quite different from the code that a typical C compiler would produce.grease's memory model is designed to work well with C compiler idioms, but perhaps not as much withrustcidioms.
As a general rule, it is wise to invoke grease with the --rust flag when
simulating Rust programs. Doing so changes some of grease's simulator
settings to be more permissive when analyzing code so that it does not
mistakenly flag common rustc idioms as undefined behavior. This is especially
important for dealing with Rust enums, as grease will often flag enum-related
code as reading from uninitialized memory unless --rust is enabled.
S-expression programs
In addition to ELF binaries, GREASE can analyze standalone programs written in the Crucible S-expression language. This is mostly useful for developers in writing test-cases for GREASE.
File naming conventions
Standalone S-expression programs must be named as follows:
*.armv7l.cblfor AArch32 syntax*.llvm.cblfor LLVM syntax*.ppc32.cblfor PPC32 syntax*.ppc64.cblfor PPC64 syntax*.x64.cblfor x86_64 syntax
Overrides follow a similar convention.
Conventions for entrypoints
Entrypoints of non-LLVM S-expression programs must take a single argument
and return a single value, both of a designated architecture-specific struct
type, representing the values of all registers. These struct types are called
AArch32Regs, PPC32Regs, PPC64Regs, and X86Regs.
For example, here is a minimal AArch32 S-expression program that swaps the
values in R0 and R1:
(defun @test ((regs0 AArch32Regs)) AArch32Regs
(start start:
(let init-r0 (get-reg r0 regs0))
(let init-r1 (get-reg r1 regs0))
(let regs1 (set-reg r0 init-r1 regs0))
(let regs2 (set-reg r1 init-r0 regs1))
(return regs2)))
For more information about this struct, see the Macaw documentation.
Register names
Each extension to the Crucible S-expression language has its own documentation, but for the sake of convenience we reproduce the register naming schemes here:
- AArch32:
- General purpose registers:
r0, ...,r10,fp(AKAr11),ip(AKAr12),sp(AKAr13), andlr(AKAr14) - Floating-point registers:
v0, ...,v31
- General purpose registers:
- PowerPC:
- General purpose registers:
ip,lnk,ctr,xer,cr,fpscr,vscr,r0, ...,r31 - Floating-point registers:
f0, ...,f31
- General purpose registers:
- x86_64:
- General purpose registers:
rip,rax,rbx,rcx,rdx,rsp,rbp,rsi,rdi,r8, ...,r15 - Floating-point registers: (no syntax)
- General purpose registers:
Each extension exports get-reg and set-reg operations, as shown above for AArch32.
Shape DSL
The goal of GREASE's refinement loop is to discover sufficient preconditions for the successful execution of a target function. These preconditions are represented as a mapping from arguments (i.e., registers) to shapes.
Abstract syntax
Conceptually, a shape has the following grammar:
shape ::=
| bv
| bv-lit byte+
| ptr memshape*
memshape ::=
| uninit N
| init N
| exactly byte+
| memptr memshape*
byte ::= 00 | 01 | ... | ff
Where:
bvrepresents a symbolic bitvector of the appropriate widthbv-lit byte+represents a concrete bitvector literalptrrepresents a pointer, thememshape*s are what it points touninit NrepresentsNuninitialized bytes of memoryinit NrepresentsNbytes of memory initialized to symbolic bytesexactly byte+represents a concrete sequence of bytesmemptrrepresents a pointer to a further allocation
At certain verbosity levels, GREASE may output these preconditions in its logs. It does so using a concrete syntax described below.
Concrete syntax
Bitvectors (bv) are represented with sequences of XX (each representing a
symbolic byte), like so:
- 32-bit:
XX XX XX XX - 64-bit:
XX XX XX XX XX XX XX XX
Bitvector literals (bv-lit) are written in hexadecimal, 0-padded on the left
to the appropriate width, and optionally prefixed with 0x. They must have an
even number of hexadecimal digits.
- 32-bit:
0bad1dea,0x0bad1dea - 64-bit:
0bad1deadeadbeef,0x0bad1deadeadbeef
Similarly, symbolic bytes (init) are written as sequences of XXs, separated
by spaces. Uninitialized bytes are written ##. Concrete bytes (exactly) are
written like bitvector literals, in hexadecimal, 0-padded on the left to a width
of 2. Pointers (ptr, memptr) are represented as an allocation number plus
an offset. The targets of pointers are shown out-of-line.
The following example shows a pointer in AArch32 register R1. The pointer
points to allocation number 00, at offset 4. Allocation 00 contains four
uninitialized bytes, followed by two initialized, symbolic bytes, followed by
the concrete bytes fe and 0a, followed by a pointer to allocation 01.
Allocation 01 doesn't contain anything at all (thus, any read from or write to
it would fail).
R1: 00+00000004
00: ## ## ## ## XX XX fe 0a 01+00000000
01:
For 32-bit architectures, the allocation numbers are 0-padded on the left to
a width of 2, whereas for 64-bit architectures, they are padded to a width of
6. The offsets are padded to the maximal number of hex digits required to write
numbers of that bit-width, namely 8 for 32-bit and 16 for 64-bit. This scheme
ensures that pointers have the same textual width as a pointer-width sequence
of bytes.
Long, repeated sequences of bytes can be written with run-length encoding.
For example, a sequence of 64 uninitialized bytes would be ##*00000040. Just
as for pointer offsets, the run length is represented as a hexadecimal number
of the size of the machine bit-width.
Specifying initial preconditions
GREASE begins its analysis with a "minimal" precondition,1 and uses its heuristics to search for a precondition that avoids errors. In many cases, GREASE's heuristics cannot find such a precondition. In such cases, you can manually specify an initial precondition from which to begin refinement.
Example
For example, consider this (contrived) program:
// test.c
#include <stdlib.h>
void test(int *p, int *q) {
if (*p == 0) {
// do some stuff
free(q);
}
// some other stuff
free(q);
}
int main() { }
GREASE's heuristics are currently insufficient to avoid the double-free, so GREASE will output something like the following:
clang test.c
grease a.out --symbol test
Finished analyzing 'test'. Possible bug: double free at segment1+0x116a
This result may be unsatisfying if you know that test will never be called with *p == 0. By specifying --initial-precondition, you can show GREASE how to avoid
the error and continue its analysis. Assuming your compiler targets x86_64
Linux (SysV ABI), write the following in shapes.txt:
rdi: 000000+0000000000000000
000000: 01 XX XX XX
This ensures that loading from p will return a symbolic bitvector with the
lowest byte set to 01. In particular, it will never be zero. Re-running GREASE
yields:
grease a.out --symbol test --initial-precondition shapes.txt
All goals passed!
Conventions
The general-purpose and floating-point registers are named according to the following schemes:
- AArch32:
R0,R1,V0, ...,V31 - PPC:
r0, ...,r31,f0, ...,f63 - x86_64:
rax, ...,r15,zmm0, ...,zmm15
For LLVM, the arguments are numbered starting from 0 and prefixed with %, so
%0, %1, ..., etc.
JSON syntax
In addition to the concrete syntax described above, GREASE supports ingesting
initial preconditions written in JSON. The schema is not yet comprehensively
documented here, see grease-exe/tests/x86/extra/json-shapes.json for an
example. GREASE parses the file passed to --initial-precondition as JSON if it
ends in .json.
Specifically, all pointer-sized bitvector-typed registers are set to pointers that don't point to anything, and all other bitvector-typed registers are set to symbolic bitvectors.
Shared libraries
grease has rudimentary support for binaries that dynamically link against
shared libraries, but with some notable caveats.
Skipping external function calls
Dynamically linked binaries can invoke external functions defined in shared
libraries (e.g., libc). Unless grease has an override
available, grease treats any invocation of a function defined in a shared
library as as no-op. grease will log that the function is skipped, but it
will otherwise not simulate it at all. If you want to intercept grease's
behavior when it invokes an external function and have it do something,
consider supplying an override for the function.
Limitations of PLT stub detection
On the architectures that grease supports, grease identifies which
functions are external by determining if the function is being invoked from a
PLT stub. Typically, a PLT stub is located in a specially marked .plt or
.plt.sec section of the binary.
Unfortunately, reliably identifying PLT stubs is
hard. Therefore, grease has
(fallible) heuristics for determining which functions have PLT stubs, and it
relies on these heuristics to determine which functions are external (and
therefore should be skipped or not).
Unfortunately, grease's PLT stub heuristics are not perfect. In particular,
grease does not have reliable heuristics for detecting PLT stubs that are
located in .plt.got sections, which are common in x86-64 binaries. If you run
grease on a binary with a PLT stub that grease cannot detect, then you will
likely get an error message stating that grease does not support the
relocation type associated with the PLT stub, e.g.,
grease: Attempted to read from an unsupported relocation type (R_X86_64_GLOB_DAT) at address 0x3ff0.
This may be due to a PLT stub that grease did not detect.
If so, try passing --plt-stub <ADDR>:<NAME>, where
<ADDR> and <NAME> can be obtained by disassembling the
relevant PLT section of the binary
(.plt, .plt.got, .plt.sec, etc.).
If this occurs, then you must supply the address and name of the PLT stub to
grease yourself. You can do so by passing --plt-stub <ADDR>:<NAME> to
grease on the command line, once for each PLT stub. (If you do not know the
name of the PLT stub, it is fine to leave <NAME> empty.) Reverse engineering
suites such as Ghidra can be effective at
determining PLT stub information.
Skipping unsupported relocations
The flag --skip-unsupported-relocs induces GREASE to populate unsupported
relocations with fresh, symbolic data rather than throwing an exception and
halting analysis.
System calls
Most programs make system calls (syscalls) via libc. GREASE provides
overrides for many functions in libc, so it is relatively rare
for GREASE to encounter a system call during simulation. However, syscalls may
still arise from direct use of instructions like x86_64's syscall, especially
in statically-linked binaries. GREASE currently has rudimentary support for such
cases. As GREASE currently only supports analyzing ELF binaries, it also only
supports Linux system calls.
GREASE's algorithm for handling syscalls is as follows:
- If the syscall number is symbolic, then:
- If
--error-symbolic-syscallswas provided, an error is generated - Otherwise, the call is skipped
- If
- Otherwise, GREASE checks for a syscall override
- If none can be found, the call is skipped
- If one is found, then it is invoked
No registers or memory are havoc'd if a system call is skipped (though this may change in the future).
Syscall overrides
GREASE currently only provides a single syscall override, for getppid. On
Linux, a parent PID can change at any time due to reparenting, so this override
always returns a fresh value.
Undefined behavior
GREASE aims to find or verify the absence of bugs in the program under analysis. This page describes generally suspicious behaviors that GREASE can detect.
What constitutes a bug? When analyzing C, C++, or Rust code, a conservative answer is that any form of reachable undefined behavior in a complete program constitutes a bug. For machine code, things aren't so clear.
Many behaviors that might be considered undesirable or undefined at the source level have well-defined semantics at the machine code level. For example, consider a C program with a stack buffer overflow into an adjacent variable. In the C abstract machine, such behavior is clearly undefined. However, if the program is compiled in a straightforward way into machine code, the distinction between different stack variables is lost. The resulting code simply performs several innocuous-looking writes to the stack. Similarly, adding two signed integers in C might result in an undefined signed overflow. At the machine code level, there is no distinction between signed and unsigned integers, and arithmetic operations generally have a well-defined semantics for all inputs (e.g., based on a two's complement representation).
GREASE aims to be pragmatic in what it calls a bug. It uses a C-like memory model, and reports behaviors of binaries that would likely constitute undefined behavior in C. However, as described above, many sources of undefined behavior are impossible or infeasible to detect at the level of machine code. The following sections detail what behaviors GREASE can and cannot check.
C11 undefined behaviors
This section describes which forms of undefined behaviors listed in the C11 standard GREASE checks for. Because the C standard does not offer a comprehensive numbering scheme, we adopt that of the back matter of the SEI CERT C Coding Standard.
The following determinations are quite nuanced. Please reach out to grease@galois.com if you have further questions about the properties checked by GREASE.
Many undefined behaviors refer to the lexical and syntactic structure of the source C program. Such behaviors are clearly out of scope for GREASE. This includes at least behaviors 2, 3, 4, 6, 7, 8, 14, 15, 26-31, 33, 34, 58, 59, and 90-96.
Additional behaviors refer to syntactic categories such as lvalues that do not have corollaries at the binary level. This includes at least behaviors 12, 13, 18-21, 36, 46, 61, 62.
Further behaviors refer to types that are not available or semantically meaningful at the binary level, such as void. This includes at least behavior 22.
The following table lists the remaining behaviors. It is far from complete, and we hope to expand it over time.
| Number | Description | Checked by GREASE | Notes |
|---|---|---|---|
| 5 | The execution of a program contains a data race (5.1.2.5). | No | See limitations |
| 9 | An object is referred to outside of its lifetime (6.2.4). | Yes | See Memory model |
| 10 | The value of a pointer to an object whose lifetime has ended is used (6.2.4). | Yes | See Memory model |
| 11 | The value of an object with automatic storage duration is used while the object has an indeterminate representation (6.2.4, 6.7.11, 6.8). | Yes | See Memory model |
| 16 | Conversion to or from an integer type produces a value outside the range that can be represented (6.3.1.4). | No | Types are not available at the binary level and all conversions are well-defined |
| 17 | Demotion of one real floating type to another produces a value outside the range that can be represented (6.3.1.5). | ? | Needs test case |
| 23 | Conversion of a pointer to an integer type produces a value outside the range that can be represented (6.3.2.3). | Somewhat | Conversions themselves are not checked, as types are not available. Some forms of pointer arithmetic raise errors. |
| 24 | Conversion between two pointer types produces a result that is incorrectly aligned (6.3.2.3). | ? | Needs test: #88 |
| 25 | A pointer is used to call a function whose type is not compatible with the referenced type (6.3.2.3). | No | Types are not available at the binary level. |
| 32 | The program attempts to modify a string literal (6.4.5). | Yes | Such literals end up in read-only memory in the binary. |
| 34 | A side effect on a scalar object is unsequenced relative to either a different side effect on the same scalar object or a value computation using the value of the same scalar object (6.5.1). | ? | |
| 35 | An exceptional condition occurs during the evaluation of an expression (6.5.1). | ? | |
| 37 | A function is defined with a type that is not compatible with the type (of the expression) pointed to by the expression that denotes the called function (6.5.3.3). | No | Types are not available at the binary level. |
| 38 | A member of an atomic structure or union is accessed (6.5.3.4). | ? |
Exceptions
Certain operations generate traps or exceptions at the processor level. GREASE attempts to treat these as errors. These include:
- Division by zero
Development
Build
To build and install from source, you'll need to install:
- GHC 9.6, 9.8, or 9.10
cabal-install3.6 or later
Follow the instructions on the Haskell installation page.
Then, clone GREASE and its submodules:
git clone https://github.com/GaloisInc/grease
cd grease
git submodule update --init
Then, build with cabal:
cabal build exe:grease
See Test suite for how to run the tests.
To build a binary suitable for releases, run the following before cabal build:
cat cabal/release.cabal.project >> cabal.project.local
Docker
GREASE also offers a nightly Docker image that gets built after each commit to
the main branch. To run GREASE on an input using Docker, run the following
docker run ghcr.io/galoisinc/grease:nightly <input>
GREASE's test suite can also be run through Docker, although it requires
changing the entrypoint to use grease-tests instead:
docker run --entrypoint grease-tests ghcr.io/galoisinc/grease:nightly
The Docker image is available for both amd64 and arm64 architectures.
Documentation
Documentation is built with mdBook. Install with cargo (or with a package
manager):
cargo install mdbook
Then build the book with:
cd doc
mdbook build
As always, see --help for more options.
Linting
See Linting.
Ignoring uninteresting changes in git blame
Git blame is often helpful for determining commits related to changing a given line. Unfortunately, large scale code automated code changes (e.g. reformatting) can pollute the blame with a commit that is not functionally relevant to the given line. This repository maintains a .git-blame-ignore-revs to ignore this type of commit. The file lists past reformatting commits. To use this file to ignore these commits when running git blame configure git with the following command:
git config blame.ignorerevsfile .git-blame-ignore-revs
Source code
The grease source code is split up into a number of smaller libraries, each
residing in its own top-level directory:
grease: This comprises the core ofgreaseas a library.grease-cli: This library contains the parsers for the CLI ofgrease-exe.grease-llvm: This extends thegreaselibrary with the ability to reason about LLVM bitcode.grease-aarch32: This extends thegreaselibrary with the ability to reason about AArch32 binaries.grease-ppc: This extends thegreaselibrary with the ability to reason about 32-bit and 64-bit PowerPC binaries.grease-x86: This extends thegreaselibrary with the ability to reason about x86-64 binaries.
Periodic tasks
The following is a list of things that should be done occasionally by GREASE developers.
- Check for out-of-date documentation
- Fix warnings from
cabal haddock - Review and triage old issues
- Create tests for issues labeled "status/needs test"
- Search for and fix broken links to the GREASE documentation
- Update versions of dependencies and tools
- Bump bounds on Hackage dependencies (
cabal outdatedcan help) - Bump submodules
- Update versions of tools used in CI:
- Cabal
- GHC (see below)
- Linters
- OS images
what4-solvers
- Update versions of tools used in the Dockerfile:
ghcup
- Bump bounds on Hackage dependencies (
GHC versions
We support the three most recent versions of GHC. We try to support new versions as soon as they are supported by the libraries that we depend on.
Adding a new version
GREASE has several Galois-developed dependencies that are pinned as Git submodules, in deps/.
These dependencies need to support new GHC versions before GREASE itself can.
First, create GitHub issues on each of these dependencies requesting support for the new GHC version.
Then, create an issue on the GREASE repo that includes:
- A link to the GHC release notes for the new version
- Links to the issues on the dependencies
- A link to this section of this document
Then, wait for the issues on the dependencies to be resolved. When adding support for the new GHC version to GREASE itself, complete the following steps:
- For each package:
-
Allow the new version of
basein the Cabalbuild-depends -
Run
cabal {build,test,haddock}, bumping dependency bounds and submodules as needed -
Fix any new warnings from
-Wdefault
-
Allow the new version of
- Add the new GHC version to the matrix in the GitHub Actions workflows
- Bump the GHC version in the Dockerfile to the latest supported version
- Follow the below steps to remove the oldest GHC version
Removing an old version
- Remove the old version from the matrix in the GitHub Actions configuration
-
Remove outdated CPP
ifdefs that refer to the dropped version -
Remove outdated
ifstanzas in the Cabal files
Error handling
The error handling policy in GREASE supports the following goals:
- Modularity: Each module of GREASE should be fairly independent of the others.
- Robustness: GREASE should be reasonably robust to unexpected inputs and circumstances.
- User-friendliness: When something goes wrong, GREASE should provide some helpful information to the user (or developer).
This document describes our general approach, but we trust one another to make exceptions to these rules as appropriate.
The ideal
The following checklist encodes our preferred error-handling strategy:
- Every fallible operation has its own error type
-
The error type implements
Pretty -
The
Prettyinstance provides substantial information on what went wrong- It may include pretty-printed representations of the data in question
- It describes why that data is unworkable
- It may provide hints about how the situation might be fixed
- The constructors of the error type are exported
-
The function returns some variant of
Either -
panicshould be used in only and all situations that are expected to be impossible to trigger using the exported API
For example:
module Foo (
Baz,
BarError(..),
bar,
) where
import Grease.Panic (panic)
import Prettyprinter qualified as PP
-- | Error type for 'bar'
data BarError
= BadBaz Baz
| UnexpectedQuux
instance PP.Pretty BarError where
pretty =
\case
BadBaz baz ->
PP.unlines
[ "The module contained a bad baz:"
, PP.pretty baz
, "Expected a baz with..."
, "Hint: try ..."
]
UnexpectedQuux -> "Found quux with..."
bar :: Baz -> IO (Either BarError BarResult)
bar =
\case
ImpossibleBaz ->
panic
"bar"
[ "Encountered `ImpossibleBaz`!"
, "This isn't possible because ..."
]
OkBaz -> undefined -- ...
Handling errors
In lib:grease, errors are generally propagated up to top-level API
entrypoints. In exe:grease-exe, they are categorized into a few different
buckets:
- User errors, e.g., an invalid configuration
- Malformed inputs (e.g., LLVM modules or binaries)
- Unsupported features
This categorization helps the user to know what to do next:
- In case of a user error, the user should revise their configuration.
- In case of malformed inputs, the user should inspect the output of the compiler or other tool.
- In the case of an unsupported feature, the user should file a bug.
This categorization essentially has to happen at the application level. Without full context, it is often not clear which errors are user errors vs. programmer errors.
No Exceptions
With a few exceptions, we disallow the use of Exceptions in GREASE.
- Exceptions are not reflected in type signatures, making it harder for developers to notice or recall when code can throw an exception. This makes it less likely for them to be handled properly.
- Exceptions tend to lack context. They can be thrown very deep in a call stack, only to be reported at the very top level.
- Exceptions can only be caught in effectful (
IO) code, making them less flexible.
We allow:
IOExceptions, which GREASE is generally not expected to be robust against.- Panics, which are unrecoverable.
We also encourage the use of Control.Exception.assert, which will be checked
when running tests but disabled otherwise.
GREASE installs a top-level exception handler that catches any uncaught exceptions and asks users to file bugs about them.
Partiality
Our policy on exceptions precludes the use of partial functions such as error,
fromJust, and undefined. In situations where the developer is tempted to
reach for such functions, they should instead use an explicit error type if the
exported API doesn't make the error unreachable, or explicitly use panic with
a message explaining why the error is in fact unreachable.
Fancy Haskell idioms
This page lists a few idioms that are used in GREASE and might be a bit surprising when you first see them. To understand these idioms, you should be comfortable with GADTs, kinds, and monads.
Types with names that start with Some
Haskell currently lacks support for first-class existential types. They can be emulated with GADTs like so:
{-# LANGUAGE GADTs #-}
data Some f where
Some :: f x -> Some f -- the return type does not mention `x`
(Some is canonically available as Data.Parameterized.Some.Some.) As
defined above, Some has kind forall k. (k -> Type) -> Type. What if you want
to existentially quantify over something of a different kind, e.g., you want to
close over the first parameter of a datatype with two parameters? Then, you have
to make your own GADT, and such types are conventionally named Some*.
Faux let-bindings in type signatures
Sometimes, a long type like AVeryLongTypeName a (AnotherLongName b) appears
several times in one signature:
foo ::
( Eq (AVeryLongTypeName a (AnotherLongName b))
, Hashable (AVeryLongTypeName a (AnotherLongName b))
, Show (AVeryLongTypeName a (AnotherLongName b))
) =>
AVeryLongTypeName a (AnotherLongName b) ->
AVeryLongTypeName a (AnotherLongName b) ->
()
foo _x _y = ()
One could define a type synonym
type ShorterName a b = AVeryLongTypeName a (AnotherLongName b)
However, this forces readers of the code to know about (and remember) the
synonym. Alternatively, one can use equality constraints to form a "faux
let-binding" like so:
foo ::
( t ~ AVeryLongTypeName a (AnotherLongName b)
, Eq t
, Hashable t
, Show t
) =>
t ->
t ->
()
foo _x _y = ()
Pattern matching on pure values in do blocks
GADT constructors can existentially quantify types.
{-# LANGUAGE GADTs #-}
data Some f where
Some :: f x -> Some f -- the return type does not mention `x`
(Some is canonically available as Data.Parameterized.Some.Some.) To use
a Some value, you generally pattern match on it. This brings the captured
variable into scope (though just as an unconstrained variable, so any code you
write after the pattern match has to be polymorphic over it).
someLength :: Some [] -> Int
someLength someList =
case someMaybe of
-- Can use l here, but have to be completely polymorphic over the element
-- type. We can use `length`, because it is polymorphic enough (it has type
-- `forall a. [a] -> Int`).
Some l -> length l
main :: IO ()
main = putStrLn (wasItJust (Some (Just "ok")))
Sometimes, we want to bring the variable into scope by pattern-matching on
the constructor, but we'd rather not use a case statement, as it increases
indentation (e.g., we might be pattern-matching on several Somes in a row).
We can't do this with let, because the type variable is only in scope for the
right-hand side of the =.
makeSome :: Int -> Some Maybe
makeSome = _ -- ...
wontWork :: IO ()
wontWork = do
let Some x = makeSome 4
-- try something with x...
pure ()
Not only will this not compile, it'll give us a confusing error message:
Couldn't match expected type ‘p0’ with actual type ‘Maybe x’
because type variable ‘x’ would escape its scope
This (rigid, skolem) type variable is bound by
a pattern with constructor:
...
However, this is possible using do-notation. Since our Some is just a
pure value (not a monadic action), we have to "inject" it into the monad using
pure:
printWasItJust :: IO ()
printWasItJust = do
Some x <- pure (makeSome 5)
-- Again, can use x here, but only polymorphically
when (isJust x) $
putStrLn "it was Just"
To understand why this works, desugar the do notation:
printWasItJust :: IO ()
printWasItJust =
pure (makeSome 5) >>= \(Some x) -> when (isJust x) (putStrLn "it was Just")
That's why you might see do pat <- pure val.
Matching on constraint-capturing constructors in do blocks
GADT constructors can "capture" constraints, which can be recovered by
pattern-matching on them. Note the lack of a Show a constraint on showIt in
the following example:
{-# LANGUAGE GADTs #-}
data Showable a where
Showable :: Show a => a -> Showable a
showIt :: Showable a -> String
showIt (Showable x) = show x -- pattern matching brings Show a into scope
main :: IO ()
main = putStrLn (showIt (Showable "hello"))
(Operationally, the GADT constructor holds the dictionary for
the class, which is like a C++ vtable, see "Internals of Type
Classes"
for more information.) GHC's built-in type equality constraint ~ is often
"captured" this way, e.g.,
{-# LANGUAGE GADTs #-}
data IsString a where
IsString :: a ~ String => IsString a
isStr :: IsString a -> a -> String
isStr is v =
case is of
IsString -> v -- can't return `v` without pattern-matching on `is`
main :: IO ()
main = putStrLn (isStr IsString "hello")
The canonical constructor for capturing equality constraints is called
Data.Type.Equality.Refl. Note that the above definition of IsString is
equivalent to writing
data IsString a where
IsString :: IsString String
which more analogous to how Refl is defined.
Sometimes, we want to bring the constraint into scope by pattern-matching on
the constructor, but we'd rather not use a case statement, as it increases
indentation (e.g., we might be pattern-matching on several Refls in a row).
This is possible using do-notation and pattern matching on a pure value,
just like with Some:
{-# LANGUAGE GADTs #-}
import Data.Type.Equality ((:~:)(Refl))
type IsString a = a :~: String
printStr :: IsString a -> a -> IO ()
printStr is v = do
Refl <- pure is
putStrLn v
main :: IO ()
main = printStr Refl "hello"
Linting
Lūn
GREASE employs a variety of linting tools, which can optionally be coordinated
via Lūn. We do our best to keep lun.toml up to date, but the ground truth of
which linters are run on what files and in what configuration is always supplied
by the CI system. To run them all:
lun run
Lūn can run just the formatters, or run the linters in "fix" mode where
applicable. See the --help output for more information.
We recommend using this as a pre-commit hook:
cat <<'EOF' > .git/hooks/pre-commit
#!/usr/bin/env bash
lun run --check --staged
EOF
chmod +x .git/hooks/pre-commit
Generic scripts
We have a few Python scripts in scripts/lint/ that perform one-off
checks. They generally take some number of paths as arguments, check
.github/workflows/lint.yml to see how they are invoked in CI.
Fourmolu
This repo enforces Fourmolu formatting based on the committed configuration in fourmolu.yaml. Installation and usage directions are available
here. In short:
cabal install fourmolu-0.19.0.0
fourmolu --mode inplace $(git ls-files '*.hs')
One can configure auto-format on save to avoid formatting issues. The repo is already formatted with fourmolu so new formatting changes should be localized to behavioral changes. Further discussion of the rationale for the enforcement of a fourmolu style and commit hygiene is available in this formatting discussion.
google-java-format / Checkstyle
The Ghidra extensions' Java sources are formatted with google-java-format
(AOSP style) and linted with Checkstyle (via Gradle's built-in checkstyle
plugin). Both run through Gradle and do not require GHIDRA_INSTALL_DIR:
(cd ghidra-ecfs && gradle lintJava) # check formatting + Checkstyle
(cd ghidra-ecfs && gradle formatJava) # apply formatting
(cd screach/ghidra && gradle lintJava) # check formatting + Checkstyle
(cd screach/ghidra && gradle formatJava) # apply formatting
The pinned tool versions live in each extension's build.gradle
([ref:ghidra_java_lint_versions]); the shared Checkstyle config is
ghidra-common/config/checkstyle/checkstyle.xml. Each extension's Nix shell
provides both tools. See ghidra-ecfs/README.md
and screach/ghidra/README.md for details.
hlint
We treat a small number of hlint warnings as errors in CI. To run hlint locally, try:
hlint grease{,-aarch32,-llvm,-ppc,-x86}/src grease-cli/src grease-exe/{main,src,tests}
mdlynx
We run mdlynx on our Markdown files to check for broken links. To run it locally, try:
git ls-files -z --exclude-standard '*.md' | xargs -0 mdlynx
ruff
We lint and format the Python linting scripts and Ghidra plug-in with ruff.
git ls-files -z --exclude-standard '*.py' | xargs -0 ruff format
git ls-files -z --exclude-standard '*.py' | xargs -0 ruff check
spotless
See the Ghidra batch plugin docs.
tagref
We lint cross-references in code with tagref.
tagref
tagref verifies that every reference refers to an existing tag, and that there are no duplicate tags. The following is the syntax of tags and references:
- Tags:
[tag:snake_case_tag_name] - References:
[ref:snake_case_tag_name]
tagref can also verify file and directory references (file: and dir:).
We often tag: the documentation for a feature, and then use ref:erences in
places in the code that have behavior described in the documentation. This helps
us remember to update documentation when we update code, and signals to readers
of the code that higher-level documentation that can provide valuable context is
available elsewhere.
We highly encourage extensive cross-referencing. It helps us keep documentation and code in sync, and reminds us what needs to be updated in other parts of the codebase when making changes.
ttlint
We lint text files with ttlint.
git ls-files -z --exclude-standard '*.cabal' '*.hs' '*.md' '*.py' '*.scala' | xargs -0 ttlint
typos
We run typos on doc/ and the Ghidra help HTML directories. To run it
locally, try:
typos doc/ ghidra-plugin/src/main/help/ screach/ghidra/src/main/help/
zizmor
We lint our GitHub Actions workflows and composite actions for security issues with zizmor. To run it locally, download a release binary and run:
zizmor .github/workflows/ .github/actions/
On-boarding
This page provides learning resources for new GREASE developers.
Binary analysis
General background
- LWN:
- The journey before
main(): Basically like "How programs get run{,: ELF binaries}" above, but with Rust-focused examples. - GDB in The Architecture of Open-Source Applications
- Phrack
- Eli Bendersky's website
- Binary symbolic execution with KLEE-Native
Try it out!
-
Use bintools
-
Read
objdumptldr, disassemble something! -
Read
readelftldr, examine an ELF file! -
Read
nmtldr, look at some symbols!
-
Read
-
- Use
llvm-dwarfdump
- Use
- Download Ghidra, look at an ELF program
LLVM
- Docs
- LLVM in the Architecture of Open-Source Applications
- A helpful blog
- Another helpful blog
- Yet one more helpful blog
- Are there seriously more blogs?
Try it out!
-
Compile a program to .ll with
clang -fno-discard-value-names -emit-llvm -grecord-gcc-switches -S -O1 test.c - Do the same thing using compiler explorer
-
Assemble it to .bc with
llvm-as test.bc, disassemble it again withllvm-dis
Under-constrained symbolic execution
- Blog post about an older tool that did this for LLVM
- Original paper about UC-KLEE: Under-Constrained Symbolic Execution: Correctness Checking for Real Code
- Follow-up paper: Sys: A Static/Symbolic Tool for Finding Good Bugs in Good (Browser) Code
Dependently-typed Haskell
GREASE and its underlying libraries are programmed using dependently-typed Haskell.
Singletons
This is the name of the approach of combining GADTs and type families to achieve dependently-typed programming. The main paper is Dependently typed programming with singletons.
The singletons library uses Template Haskell where parameterized-utils encourages a more explicit style.
parameterized-utils
This is our core dependently-typed programming library.
Idioms
See Fancy Haskell idioms for some examples of idioms that arise when doing "fancy" Haskell programming.
Try it out!
Libraries
GREASE makes use of several libraries for binary analysis and symbolic execution.
Macaw
Macaw performs code discovery: given some set of entrypoints (generally addresses of functions, generally from the symbol table), Macaw recovers the CFGs (bounds of and edges between basic blocks) and translates them into its own IR. Macaw CFGs can then be turned into Crucible CFGs for symbolic execution.
- arXiv paper: https://www.arxiv.org/pdf/2407.06375
- API documentation
- GitHub (warning: not well documented)
- Memory model blog post
The closest thing out there to the Macaw/Crucible combo is angr.
Try it out!
Prepare to build Macaw (see the latest build instructions in the README):
git clone https://github.com/GaloisInc/macaw
cd macaw
git submodule update --init
ln -s cabal.project.dist cabal.project
Then print the Macaw CFGs in a test ELF file:
cabal run exe:macaw-x86-dump -- discover x86_symbolic/tests/pass/identity.opt.exe
Pass --crucible to see the Crucible CFGs too.
Crucible
Crucible is an imperative IR. It has an SSA format with basic blocks. It uses dependently-typed programming to enforce well-typedness and the SSA invariant. It comes with a symbolic execution engine. There are many frontends that translate other languages into the Crucible IR, e.g., LLVM (e.g., from C and C++ via Clang), JVM (e.g., from Java), MIR (e.g., from Rust), WebAssembly, and crucially for us, machine code (via Macaw).
Try it out!
First, install Yices and Z3. Then, Prepare to build Crucible (see the latest build instructions in the README):
git clone https://github.com/GaloisInc/crucible
cd crucible
git submodule update --init
The run Crucible on some example IR files:
cabal run exe:crucible -- simulate crucible-cli/test-data/simulate/assert.cbl
What4
What4 is our internal representation of symbolic terms. What4 values are manipulated by Crucible programs. What4 wraps a variety of SMT solvers to make queries about terms.
- GitHub
- API documentation on Hackage
- Recently added API docs (not yet on Hackage):
Ghidra script development
Type stubs for autocomplete
Partial autocomplete can be enabled for the Ghidra script (ghidra_scripts/grease.py) by installing the upstream distributed
Python stubs.
Using virtualenvwrapper one can setup the stubs by running:
mkvirtualenv ghidradev
workon ghidradev
pip install ghidra-stubs
Editors that support type stubs will be able to use this virtualenv to provide partial autocomplete support.
Linting
See the linting section of the dev docs for discussion of how to lint this script with ruff.
Ghidra batch plugin development
Formatting
The Scala files in the Ghidra batch plugin can be formatted with scalafmt by running ./gradlew spotlessApply from the ghidra-plugin directory.
Glossary
This page attempts to define and especially disambiguate specialized terms that may arise when reading about or developing GREASE.
Control-flow graphs
"CFG" stands for "control-flow graph". See:
In the context of GREASE, there are a few different kinds of CFGs:
- Macaw CFGs, which arise from code discovery:
Data.Macaw.CFG.Core - Crucible CFGs, which can be symbolically executed:
- In SSA form:
Lang.Crucible.CFG.Core - In "registerized" form:
Lang.Crucible.CFG.Reg
- In SSA form:
The macaw-symbolic package transforms Macaw CFGs into Crucible CFGs.
Similarly, "expression" or "statement" may refer to expressions or statements in any of the above CFGs.
Memory
In the context of GREASE, "memory" may refer to:
- Actual run-time memory (i.e., RAM) of a program under analysis
- Macaw memory, which is a pre-loader representation of the memory layout
extracted from metadata in a binary:
Data.Macaw.Memory - The Crucible-LLVM memory model
Lang.Crucible.LLVM.MemModel, which serves as the representation of memory during symbolic execution. - GREASE's memory model, which is essentially that of Crucible-LLVM mediated by the Macaw Crucible language extension. See Memory model.
Common abbreviations and acronyms
- AArch32: 32-bit ARM ISA
- ABI: Application binary interface
- AMD64: Another name for x86_64
- Armv7l: A particular instantiation of AArch32
- ASL: ARM Semantics Language
- bc: LLVM bitcode
- CFG: Control-flow graph, see above
- ctx: "Context", sometimes
Data.Parameterized.Context - DWARF: This is not an acronym, but is a binary format for debugging information designed for use with ELF
- ELF: Executable and Linkable Format
- GHA: GitHub Actions
- GHC: Glasgow Haskell compiler
- GOT: Global offset table
- IR: Intermediate representation, usually of a compiler (e.g., LLVM IR)
- ISA: Instruction set architecture, e.g., AArch32 or x86_64
- ld: Loader (or linker)
- ll: Human readable format for LLVM IR, as opposed to LLVM bitcode
- LLVM: This is not an acronym. See https://llvm.org/.
- PLT: Procedure linkage table
- PPC: PowerPC
- reloc: ELF relocation
- rtld: Run-time loader
- SMT: Satisfiability modulo theories
- symex: Symbolic execution
- SysV: System V ABI, the ABI of x86_64 Linux
- uc-symex: Under-constrained symbolic execution
Development practices
This document describes the current development practices of GREASE maintainers. It is descriptive, not normative. The idea is to make it easy for new contributors to get started.
We generally try to balance the goals of producing high-quality (featureful, correct, maintainable) software with experiencing joy during its development. Happily, these goals often coincide rather than conflict.
Our practices are generally rooted in substantial trust in one another's judgment, grounded in a sense of shared goals and direction. In particular, we trust one another to make exceptions and ignore or modify conventions whenever it makes sense to do so.
In brief
- We use GitHub issues to track upcoming work.
- We make changes via pull requests and require review and approval before merge.
- We review in a timely manner (generally within one business day).
- We have no recommended merge strategy (squash vs. rebase vs. merge commit).
- We use automated testing and CI pervasively.
Pull requests
The following state diagram shows our normal pull request (PR) workflow. The transitions are labeled by actions by the Author and Reviewer. Some points to note:
- We generally expect that each comment thread in a PR review will be "resolved", most often by (1) answering the question therein, (2) making a change to the PR, or (3) explicitly deferring the change to a new issue and adding a numbered TODO (see Style). Authors or reviewers may resolve comment threads as appropriate.
- Reviewers often approve before all threads are resolved, trusting the author to appropriately address them before merging.
- The author requests a new review when they have made substantial changes after approval. Whether a change is substantial enough to warrant another review is left to the author's judgment.
- The author (rather than the reviewer) merges the PR. We have no recommended/default merge strategy (squash vs. rebase vs. merge commit). Instead, we make a decision in each case that supports a comprehensible git history. We assume developers are familiar with the trade-offs between these options.
┌───────────────┐
│ Issue │
└───────────────┘
│
│ A: Assign to self
▼
┌───────────────┐
│ In progress │ ─────────────┐
└───────────────┘ │
│ │
│ A: Open draft PR │
▼ │
┌─── ┌───────────────┐ │ A: Open PR
A: Revisions │ │ Draft PR │ │
└──⏵ └───────────────┘ │
│ │
│ A: Mark PR as ready │
▼ │
A: Revisions ┌─── ┌───────────────┐ ⏴────────────┘
R: Comments │ │ PR │
└──⏵ └───────────────┘ ⏴───┐
│ │
│ R: Approve │ A: Re-request review, or
▼ │ R: Un-approve
┌─── ┌───────────────┐ ────┘
A: Revisions │ │ Approved │
└──⏵ └───────────────┘ ⏴────────────┐
│ │
│ CI passes, and │ CI fails, or
│ Comments are resolved │ R: Comments
▼ │
A: If needed, ┌─── ┌───────────────┐ ─────────────┘
rewrite git │ │ Ready │
history └──⏵ └───────────────┘
│
│ A: Merge
▼
┌───────────────┐
│ Merged │
└───────────────┘
Issue labels
We use GitHub issue labels to organize our issues and PRs. This requires a modicum of effort, but can make it substantially easier to find something you're looking for down the line.
Our labels form a filesystem-like hierarchy, with / used as a separator. The
top-level "directories" are:
area/: The part(s) of the codebase and/or domain of interest that are relevant to this issue/PR.size/: How big and/or difficult it would be to fix this issue.status/: Where this issue/PR is in its lifecycle (see below).topic/: The sort of improvement this issue/PR targets. Examples includetopic/performance,topic/tech debt,topic/ux.type/: Whether this is a bug report, feature request, refactoring idea, or question.
You can find a comprehensive list of labels in the GitHub label UI. Almost all of them have individual descriptions.
type/ and size/ labels are mutually exclusive. topic/ labels are usually
mutually exclusive.
status/
The status/ labels describe where an issue is in its lifecycle. They mostly
apply to bugs. The notional workflow is a progression through the following
stages, though several might be skipped along the way:
status/needs repro: The issue does not have sufficient information to reproduce the reported bug.status/needs mcve: The issue has sufficient information to reproduce the reported bug, but it is not sufficiently simple (i.e., not a minimal, complete, and verified example).status/needs test: The issue has an MCVE, but lacks an in-repo expected-failure test tracking the completion of the ticket.
Each of these has a corresponding status/has * label.
Profiling
GREASE includes functionality for profiling its performance. To generate a
profiling report, pass --profile-to <DIR> to GREASE. This will generate a
<DIR>/profile.html file that can be viewed in a web browser. The data that
this HTML file presents will be periodically regenerated as GREASE runs on the
program. A typical example looks like:
The profiling report presents a hierarchical view of the functions that are invoked during the simulation of a program. The x-axis represents the time, and the y-axis shows the call stack depth, counting from zero at the bottom. Each stack frame is given a score based on some simulator heuristics (the time spent simulating it, its number of allocations, its numbers of merges, etc.). Generally speaking, the higher the score, the more likely it is to be a performance bottleneck.
Style
This document describes a few aspects of the coding style in use in GREASE. The main idea is to document expectations that frequently arise as comments during code review. We strive to document our consensus, rather than enforce opinions. We trust one another to make exceptions to these rules as appropriate. We currently do not provide much in the way of justification for these guidelines, but may do so in the future.
Some of these expectations are codified and enforced in CI using automated tooling such as GHC warnings, hlint, or ad-hoc scripts.
This is a description of practices we have found useful in the context of GREASE, not a recommendation or prescription for other projects or contexts.
Error handling
See Error handling.
Exports
Every module has an explicit export list.
Haddocks
Exported functions and types are documented with Haddock.
Imports
Imports are qualified or have explicit import lists. Qualified imports are written in postpositive position. Imports are in one large block that is alphabetically sorted.
Naming
Functions and variable names are written in camelCase. Type, class, and module
names are written in UpperCamelCase.
Newtypes
newtype's are used frequently. This post has a discussion of the
practice in Rust, which applies mutatis mutandis to Haskell.
Numbered TODOs
TODO comments are used liberally, and are formatted TODO(#NNN) where #NNN
is a GitHub issue number.
Superfluous syntax
We avoid superfluous syntax. For example, we avoid writing f $ x or f (x)
when just f x would do. A common case is a superfluous do. Instead of
f :: a -> IO b
f x = do
g x
Write:
f :: a -> IO b
f x = g x
Test suite
To run the tests:
$ cabal test pkg:grease-exe
The tests reside in the grease-exe/tests/ directory. They are automatically
discovered by the test harness based on their file name. They are written using
Oughta.
We divide the tests into two general categories: (1) tests involving binaries, and (2) tests involving LLVM bitcode or S-expression files.
Binary test cases
These test grease's machine code frontend by ingesting binaries. These test
cases are organized into different subdirectories:
-
refine/: Tests that exercise the precondition refinement process. Subdirectories:a.
bug/: tests that encounter an error that grease can't work around that might be a bugb.
pos/: "true positives", tests that have some sufficient precondition for successful execution, and grease finds itc.
neg/: "true negatives", tests that have no sufficient precondition for successful execution, and grease can't find oned.
xfail-pos/: "false positives", i.e., type I error, tests that have no sufficient precondition for successful execution, but grease still "finds" onee.
xfail-neg/: "false negatives", i.e., type II error, tests that have some sufficient precondition for successful execution, but grease can't find it -
sanity/: Tests that exercise earlier or more fundamental parts ofgrease, such as disassembly or machine code semantics. For these tests, we don't particularly care whethergreasefinds a refined precondition. This directory has a few subdirectories:a.
pass/, for tests that don't cause any issuesb.
xfail-panic/, for tests that cause unhandled exceptions ingreasec.
xfail-iters/, for tests that cause unbounded iterations of the refinement loop
xfail tests may represent known bugs, or yet-to-be-implemented improvements. In this case, it's helpful to add a comment to the top of the C source file referring to a specific issue that describes the bug or feature, and to additionally provide a short synopsis of that issue. xfail tests may also represent fundamental limitations of the tool's architecture or design that are not expected to be fixed, in which case the comment should instead describe this limitation (or point to documentation that does).
To add a new test, add a new directory under the appropriate directory above. It should contain at least one of the following executables:
- A 32-bit ARM ELF executable named
test.armv7l.elf - A 32-bit PowerPC ELF executable named
test.ppc32.elf. (At the moment, we don't include 64-bit PowerPC executables, but we could if the need arose.) - An x86_64 executable named
test.x64.elf.
LLVM bitcode and S-expression test cases
Test cases that do not involve binaries fall into this category. They are organized into different subdirectories:
-
llvm/: LLVM CFGs (via crucible-llvm-syntax). Each of these test cases has the file extension*.llvm.cbl. -
llvm-bc/: LLVM bitcode files (viagrease's LLVM frontend). Each of these test cases has the file extension*.bc. Files in this directory may specify additional flags to be passed to the C compiler, see "Embedded C compiler flags" below. -
arm: AArch32 machine-code CFGs (viamacaw-aarch32-syntax). Each of these test cases has the file extension*.armv7l.cbl. -
ppc32: PPC32 machine-code CFGs (viamacaw-ppc-syntax). Each of these test cases has the file extension*.ppc32.cbl. -
x86: x86-64 machine-code CFGs (viamacaw-x86-syntax). Each of these test cases has the file extension*.x64.cbl.
Feature tests
Tests located in the feat/ directory may be binaries, bitcode, or S-expression
programs. They are intended to focus on features of GREASE other than
refinement.
UX tests
Tests located in the ux/ directory may be binaries, bitcode, or S-expression programs.
They are intended to test the User eXperience (mostly, the log output) of GREASE.
Lua API
The test harness provides the following Lua API, which enriches that of Oughta with GREASE-specific functionality. The API is presented with Haskell-style type signatures:
prog: The name of the program under test, e.g.,"test.llvm.cbl".go(prog_name): Run GREASE with the given string as the name of the program. Frequently,progis passed as the argument, e.g.,go(prog).gomay be called multiple times per test, seefunc-ptr.llvm.cblfor an example.flags(fs): Append the given flags to the arguments passed to GREASE whengois invoked. The flags are cleared aftergois run.
It is common (though not necessary) to define a function named test and to
specify it as the only entrypoint:
// all: flags {"--symbol", "test"}
// all: go(prog)
void test(/* ... */) { /* ... */ }
Embedded C compiler flags
Tests in the llvm-bc/ directory may embed additional flags to pass to the C
compiler using the special comment syntax // CFLAGS: , e.g., // CFLAGS: -g.
The script that extracts these flags also supports flag groups, which start
with $. The only flag group currently supported is $LLVM, which expands to
-emit-llvm -frecord-command-line.
Writing good tests
The Rust Compiler Development Guide has some helpful guidance on writing high-quality tests. The GREASE test suite is generally quite similar in structure to that of rustc, so almost all of the advice there applies mutatis mutandis.
Coverage
To enable collection of coverage information, run the following:
cat cabal/coverage.cabal.project >> cabal.project.local
This will configure Cabal to collect coverage information for the grease and
grease-exe packages, but not for any of their dependencies.
Unfortunately, you'll have to force Cabal to recompile GREASE and all of its dependencies for these changes to take effect.
cabal clean
cabal build
Now, run the test suite:
cabal test pkg:grease-exe
Finally, run a report. Note that this script is best-effort and some adjustment may be required for new platforms or Cabal/GHC versions.
./scripts/coverage.sh
Alternatively, generate an HTML report with
./scripts/coverage.sh markup
You should see the report at hpc_index.html.